Token-Maxing Is Not a Strategy

95% of enterprise AI pilots deliver zero P&L impact. That is the finding from the joint MIT Sloan / BCG study of 400+ early-stage enterprise AI deployments. Seven hundred and seventeen times is the cost gap between a $500 proof-of-concept and its $847,000/month production deployment, as documented in the Token Cost Trap analysis. The same pattern repeats across hundreds of companies: small pilot, positive results, full rollout, budget crisis.
The root cause is a category error. Companies adopt the "token-maxing" philosophy from YC General Partner Diana Hu's 2026 Startup School playbook without checking whether their business model matches the companies that made it work. Token-maxing is not a universal strategy. It is contingent on a single question: is inference your product, adjacent to your product, or a cost center?
Most companies cannot answer this question until their AI budget is gone.
The Three Regimes of Inference Economics

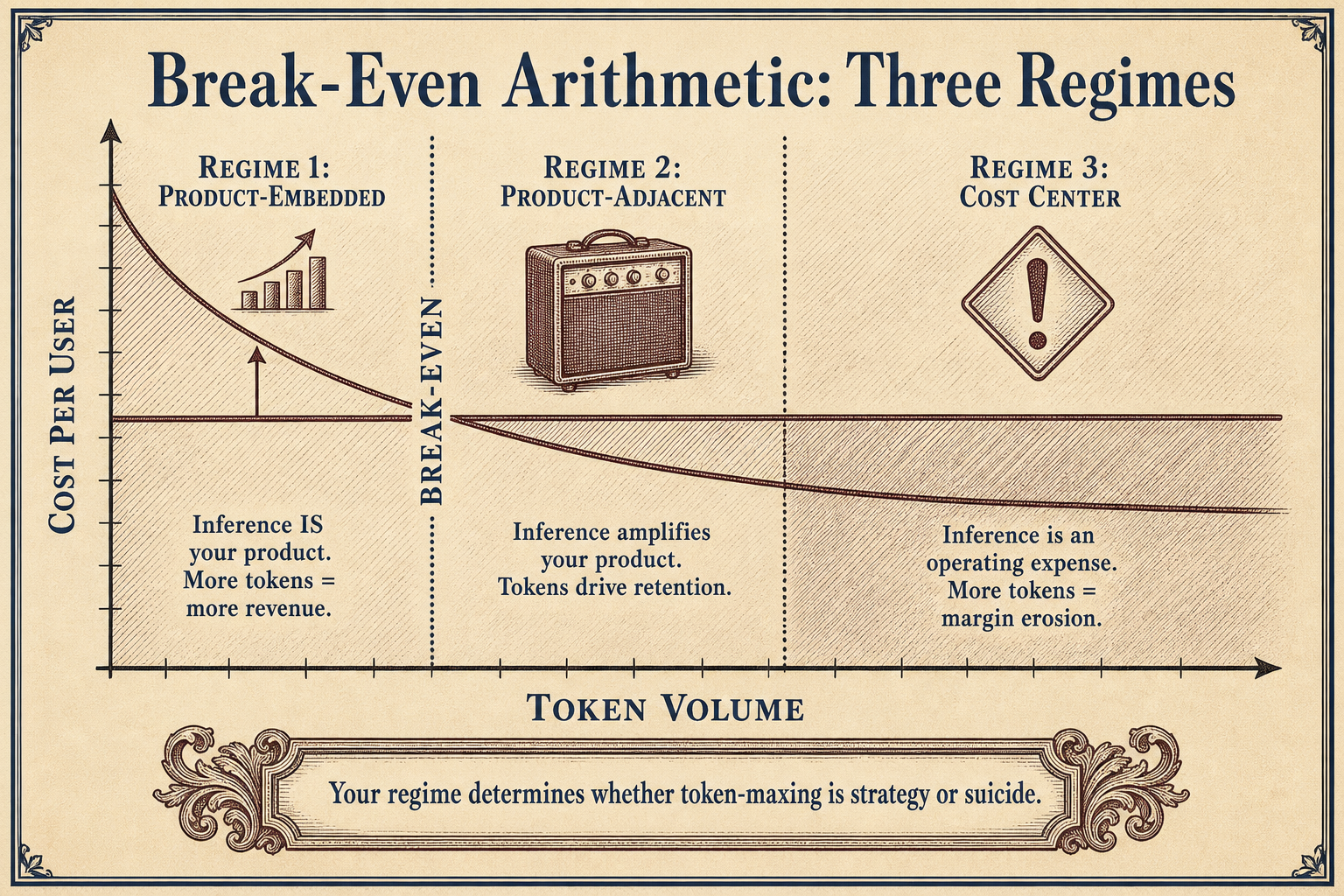
Regime 1: Product-Embedded — Inference IS Your Product
Cursor spent $1.23 in API costs for every dollar of revenue in its early stage, per Dealroom's Anysphere profile. That is a negative gross margin on the surface. It was also the fastest B2B growth trajectory in history — from $100M ARR in January 2025 to $1B+ ARR by November 2025, according to GetLatka. Cursor's API spend was not a cost of doing business. It was the product itself. Every API call generated a coding experience that created a "wow moment," which spread through virality and replaced sales and marketing spend entirely.
Midjourney built the same model without any venture capital at all, reaching $500M ARR on 107 to 163 employees with zero VC and zero marketing budget, according to Sacra. Their cost structure is dominated by GPU inference compute, balanced against subscription revenue. Revenue per employee: approximately $3 million to $4.6 million.
In the product-embedded regime, more tokens means more product quality, which means more revenue, which means more tokens. The loop is virtuous. Gross margins look bad on paper (Cursor at negative margins early on), but unit economics improve with scale as the company optimizes model choice, caching, and eventually builds its own inference stack — which Cursor did in November 2025.
The signal: Your customers pay you for the AI output directly. If your API goes silent, your product stops working.
Regime 2: Product-Adjacent — Inference Amplifies Your Product
Gamma, the AI presentation platform, reached $100M ARR with roughly 50 employees, reported TechCrunch. Inference costs are real, but they sit inside a product that already had a pricing model and a distribution channel. The AI layer is a feature that drives conversion, not the product itself. Gamma was profitable since 2023, before the AI boom fully arrived, according to Sacra.
Product-adjacent companies can token-max aggressively, but they have a cushion their pure cost-center peers lack: the product still works without AI. The AI layer lifts retention, expands average revenue per user, and creates switching costs. The token bill is an investment in product quality, not a survival expense.
The signal: Your product has a reason to exist before the AI layer. The AI is a multiplier, not the core unit of value.
Regime 3: Cost Center — Inference Is an Operating Expense
Uber deployed Claude Code to 5,000 engineers. Per-user costs ran $500 to $2,000 per month. The company burned its entire 2026 AI budget in four months, as Artificial Intelligence Made Simple reported. Uber's core business is moving people and food. Inference does not generate revenue for Uber. It is an internal productivity tool whose costs flow through the P&L as operating expense, not cost of goods sold.
This is the largest category of AI deployment today. Enterprise internal tools. Employee productivity agents. Knowledge management chatbots. These are not products. They are cost centers. And token-maxing inside a cost center is a budget crisis waiting to happen because there is no revenue expansion to absorb the API bill.
The signal: Your AI bill comes out of the operations or IT budget. No customer sees it. No customer pays you more because of it.
The Scale Gap Destroys Pilot Economics
A single conversation averaging $0.14 in API cost translates to $4,200 per day at production scale — 3,000 employees times 10 daily interactions, as the Token Cost Trap analysis calculates. One team watched a $500 one-month proof of concept rocket to $847,000 per month upon deployment. That is a 717-times increase.
Pilot economics are misleading because token consumption is not linear. Agentic tasks consume up to 1,000 times more tokens than chat-based coding interactions, according to a study on how AI agents spend money. Token usage on the same task varies by up to 30 times, Stanford's Digital Economy Lab found. Models cannot accurately predict their own token consumption — the same arXiv study found the correlation between predicted and actual cost maxes out at 0.39.
Most companies do not discover which regime they occupy until they hit the scale gap. At pilot scale, every use case looks like product-embedded or product-adjacent. At production scale, the cost center economics become undeniable.
Break-Even Arithmetic: The Lens That Exposes the Regime
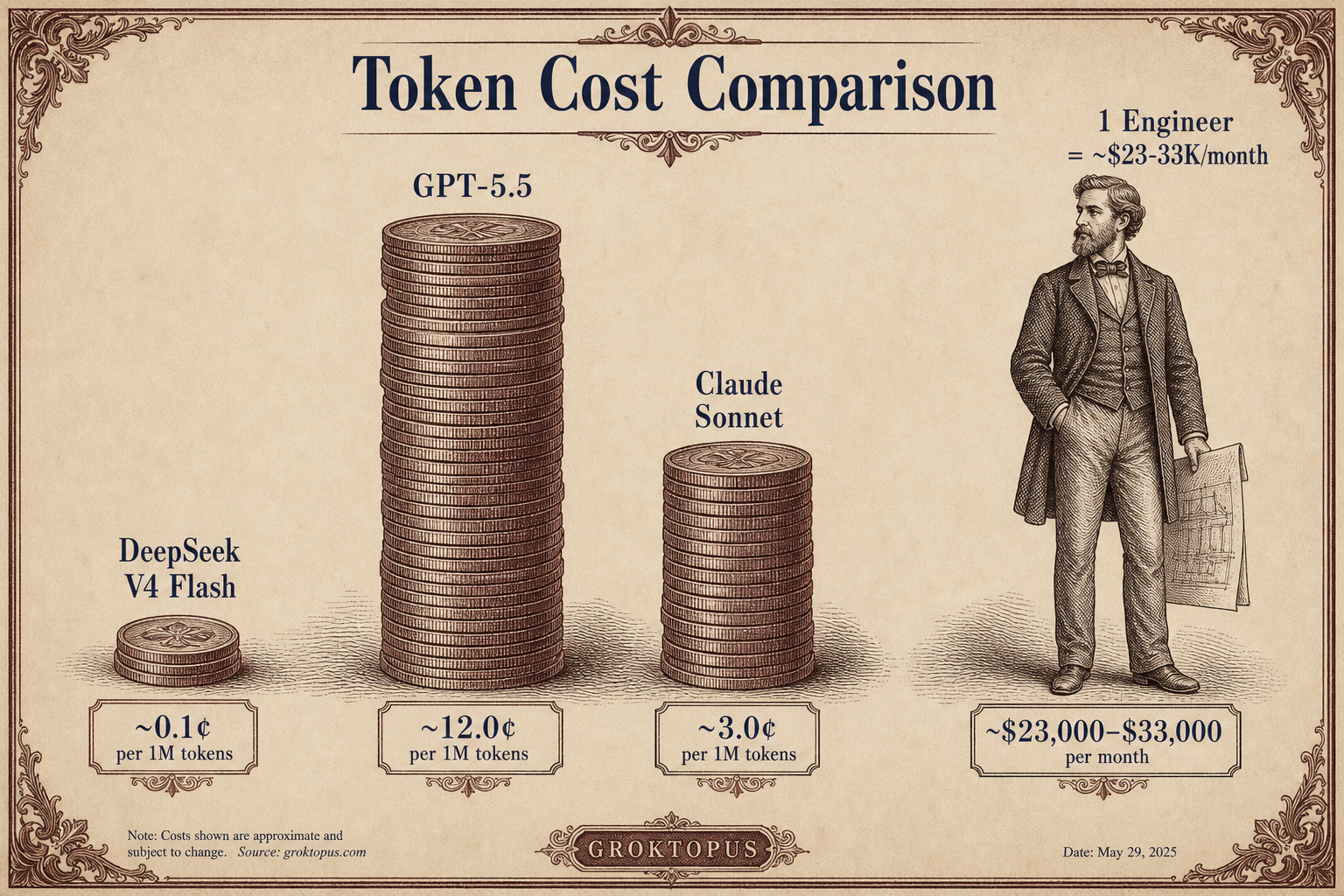
One mid-level engineer in Silicon Valley costs $23,000 to $33,000 per month fully loaded, according to Signify Technology and WhatIsTheSalary. That same $23,000 buys roughly 82 million input tokens and 82 million output tokens on DeepSeek V4 Flash pricing ($0.14/$0.28 per million tokens). On GPT-5.5 pricing ($5/$30 per million tokens), the same budget buys roughly 760,000 input and 76,000 output tokens — a 100-times difference in capacity, per CloudZero's LLM pricing comparison.
The SaaStr framing puts it bluntly: human SDR and AE labor costs $100,000 to $130,000 per year versus AI agents at $10,000 to $15,000 for basic and $50,000 to $100,000 for enterprise. Inference costs are not a gross margin problem. They are a customer acquisition cost replacement.
This framing works perfectly for Regime 1 and Regime 2 companies. For Regime 3 companies, there is no analogous revenue line to offset. The cost replacement math requires a replacement — if you are not eliminating headcount, you are not replacing cost, you are adding it.
The Pairing Metric Problem

Token-maxing without a pairing metric creates perverse incentives. When leadership mandates high token usage, employees consume tokens without regard for outcomes. This is not a hypothetical — it was raised in direct response to Diana Hu's talk on Instagram in May 2026. Max Schoening, Head of Product at Notion, described the same dynamic on Lenny's Podcast: "Leadership is mandating AI adoption and creating perverse incentives like token-maxing, while the actual productivity benefits remain uneven and hard-won."
The cynical interpretation, as Artificial Intelligence Made Simple notes, is that labs push token-maxing because internal employees serve as highly paid beta testers generating telemetry on model failure points. Whether intentional or not, the incentive alignment works for the model provider, not the customer.
The pairing metric debate is unresolved. Revenue per token? Customer outcome per token? Time saved per token deployed? Without a matching constraint, token-maxing is a blank check.
Logarithmic Gains, Super-Linear Costs
The value of an agentic loop is logarithmic: using AI agents on the right problem is highly productive, but applying the same approach to every problem produces a steep output falloff. The cost curve is super-linear: as an agent works, context window grows, and every subsequent step requires re-reading all previous context, Artificial Intelligence Made Simple explains.
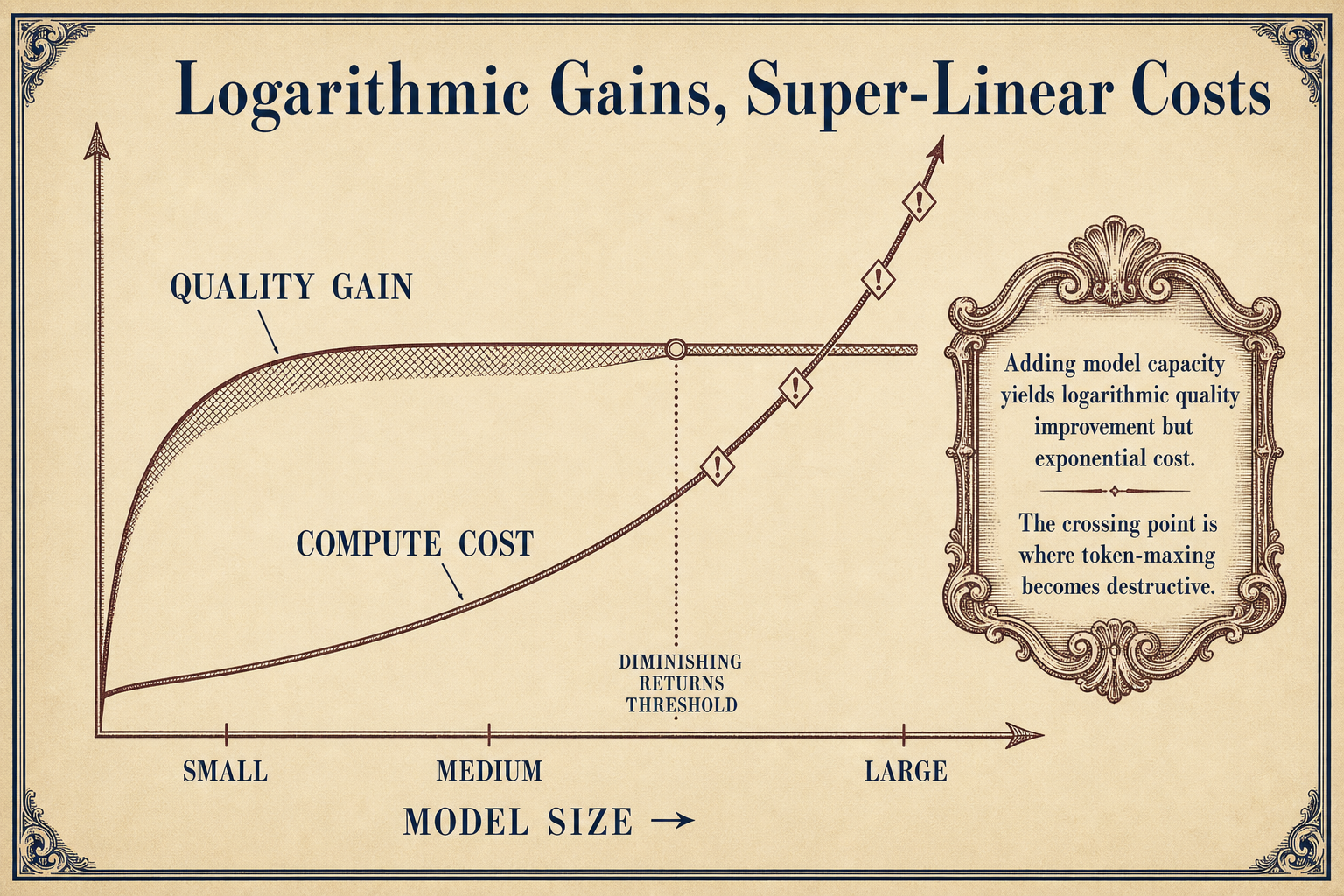
Toby Ord from Oxford identifies a "sweet spot" in the cost-performance curve: before the sweet spot, increasing marginal returns; after it, diminishing marginal returns that compound rapidly, as he explains in his analysis of AI agent costs. The research confirms what practitioners are discovering empirically: higher token spend does not translate to higher accuracy. An arXiv study found that accuracy peaks at intermediate cost and saturates.
Token-maxing assumes that more tokens means better outcomes. The evidence says otherwise.
When to Token-Max, When to Cap
Token-maxing works when three conditions are met. First, inference is product-embedded or product-adjacent — your revenue expands with token consumption. Second, your unit economics include a pairing metric that ties token spend to business outcomes. Third, you have architectural discipline: prompt caching (90% reduction on reused context), history summarization (70 to 90% reduction over long sessions), model routing (5 to 10 times cheaper per call), and code execution (98.7% reduction by replacing context bloat with deterministic logic), as the Token Cost Trap analysis outlines.
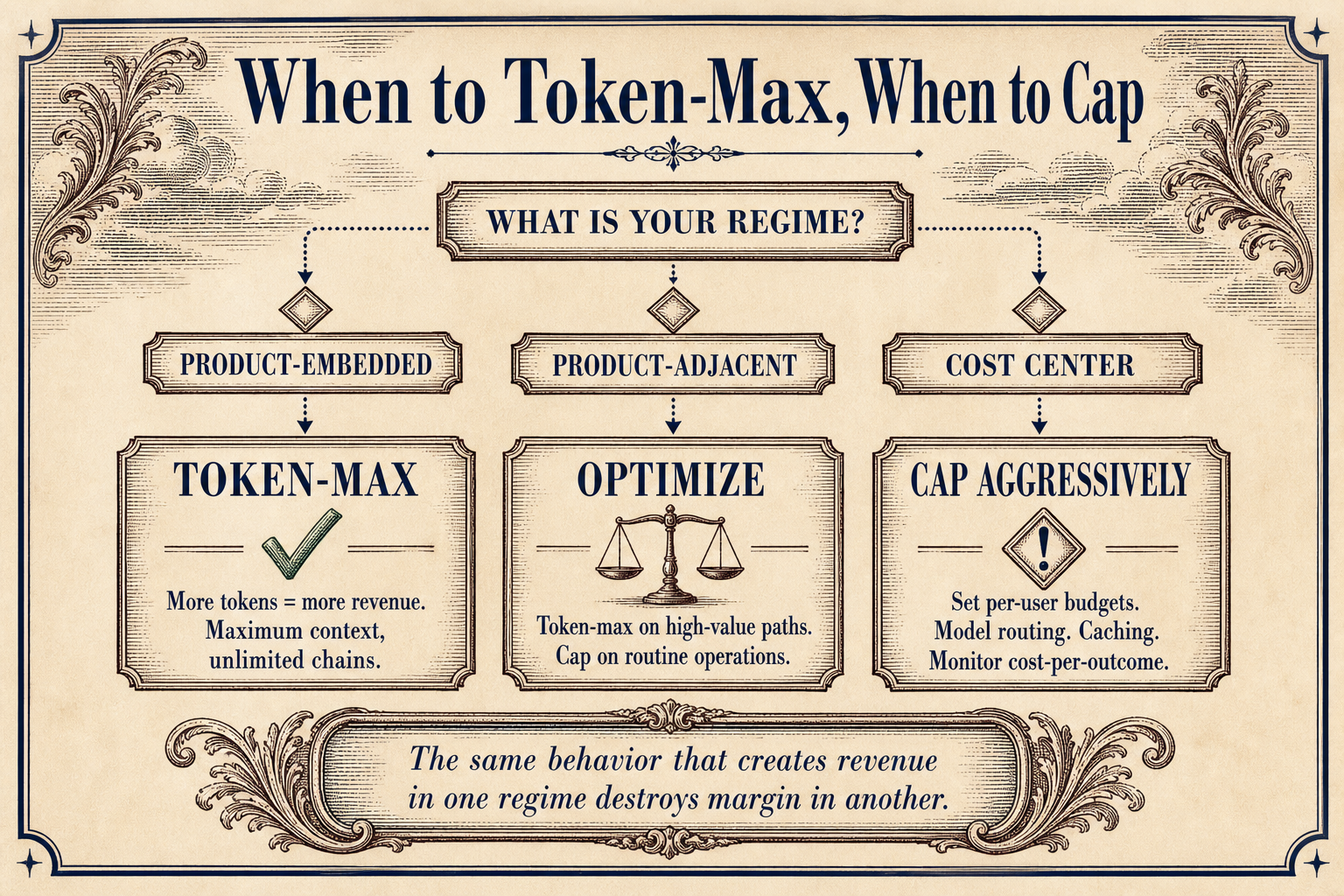
Token-maxing fails when inference is a pure cost center with no revenue offset, when there is no pairing metric to constrain waste, and when agentic loops run unbounded without architectural cost controls. The Uber case is the warning. The $500 to $847,000 scale gap is the mechanism.
Most companies do not know which regime they occupy. They test in pilot, see positive results, deploy at scale, and discover the hard way that inference economics do not generalize. The difference between Cursor and Uber is not intelligence, talent, or execution quality. It is the simple fact that Cursor sells inference and Uber consumes it.
Token-maxing is not a strategy. It is a context-dependent tactic that only reveals its fit after the budget is gone.