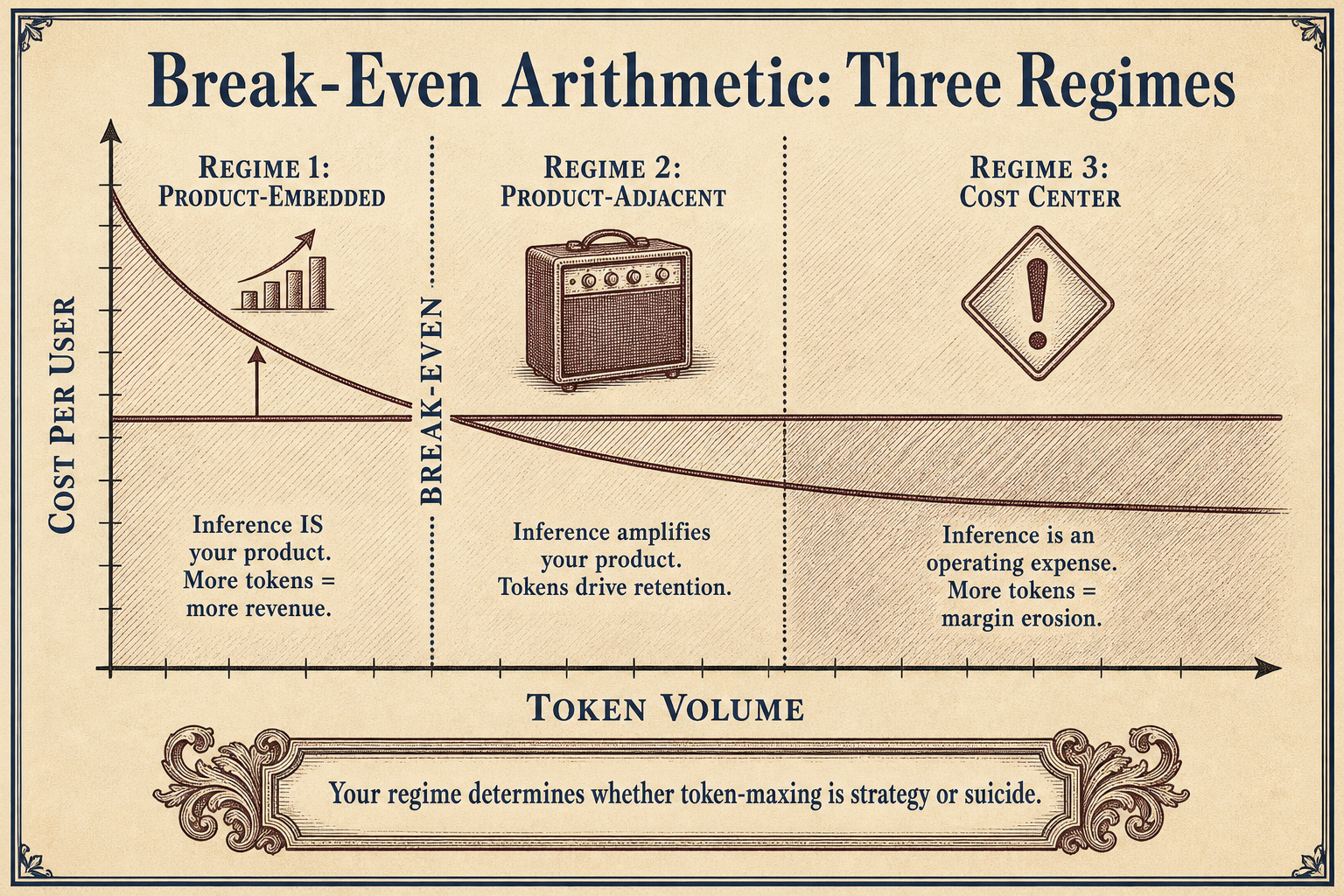
Your AI Pilot Economics Are Lies

The $500 POC That Cost $847,000 a Month
Your $500 proof of concept is lying to you. Not by accident. Systematically.
One team ran a pilot. A single AI agent handling customer conversations. Cost per conversation: $0.14. Total pilot spend: $500. The team celebrated. The board approved full deployment.
At production scale — 3,000 employees, ten interactions daily — that $0.14 conversation became $4,200 per day. Then $126,000 per month. Then $847,000 per month — as documented in the Token Cost Trap analysis. A 717x increase from the pilot number that got the project approved.
The team discovered the actual cost structure only after the budget was already burned. That is not bad planning. That is a structural feature of how enterprise AI pilots are designed, sold, and evaluated.
The Pilot Is a Gilded Fable
Enterprise AI pilots share a common pathology. They run on:

Run the same agent on the same task twice. You will not get the same token count. Not close.
Stanford researchers and the Stanford Digital Economy Lab tracked token consumption across identical agent runs. Costs varied by up to 30x on the same task, as reported by the Stanford Digital Economy Lab. Not 10 percent. Not 2x. Thirty times.
The arXiv paper "How Do AI Agents Spend Your Money?" (April 2026) confirmed this across multiple model families. Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, and Pei found that token usage is highly variable and that models fail to predict their own token consumption with any accuracy (correlation up to only 0.39). Models systematically underestimate real costs because trajectory length is inherently stochastic.
Your pilot ran five perfect conversations at 1,500 tokens each. Your production system runs 500,000 conversations where the model gets confused, retries, backtracks, and loops. The variance compounds. The budget evaporates.
Force 1: 30x Token Variance
The most obvious gap is also the easiest to ignore. A pilot uses carefully curated, short prompts. A production system handles real user queries with unpredictable context lengths. The difference in token consumption between these two conditions is rarely less than 30x.
Consider a customer support chatbot. During the pilot, every query is 200 tokens. Support agents have carefully written test cases. The demo runs perfectly. In production, real customers paste entire email threads. They ask follow-ups that reference conversations from three weeks ago. Context windows fill to 8,000, 16,000, or 32,000 tokens. The cost per query multiplies by 30 before any other factor is considered.
This is not a failure of planning. It is a structural property of the gap between curated demos and real usage. Every pilot team knows this. Almost none of them model it in their cost projections.
Force 2: 1,000x Agentic Token Multipliers
This is the big one. The difference between a chat completion and an agentic loop is not linear. It is geometric.

Pilots pretend costs scale linearly. They do not. Full stop.
Toby Ord at Oxford mapped the cost-performance curve for AI agents. He identified a sweet spot: before the sweet spot, increasing marginal returns (time horizon grows super-linearly in cost). After the sweet spot, diminishing marginal returns set in, as documented in his analysis of hourly costs for AI agents. The curve has an inflection point. You cannot predict where it sits from a pilot.
The same Stanford paper on token economics found that higher token usage does not translate to higher accuracy. Accuracy peaks at intermediate cost and then saturates. Spend more tokens past that point and you get no additional quality.
So not only do costs scale non-linearly. Value does not scale with them. The gap between cost and value widens as you scale.
Force 3: Non-Linear Scale-Up
The third force is the most dangerous because it is invisible during a pilot. As user count grows, AI cost does not grow linearly. It grows super-linearly.
Latency requirements tighten as user count rises. A 5-second response is acceptable for a pilot with 50 users. At 50,000 users, sub-second latency is table stakes. Achieving sub-second latency requires faster models, which cost more per token. It also requires parallel processing, which multiplies token consumption.
Concurrency multiplies costs in the same non-linear pattern. The pilot serves one request at a time. Production serves thousands. Each concurrent request requires its own context window. The cost of memory grows with active users, not total users. At peak, every user holds a full context window in the model's attention. That cost is invisible in a single-user demo but dominates the production budget.
The Uber Example: $10 Million in Four Months
When Uber deployed Claude Code to 5,000 engineers, per-user costs hit $500 to $2,000 per month, according to an analysis of token maxing in the AI industry. The company burned its entire 2026 AI budget in four months. Four months. At the low end of that range ($500/user/month), that is $2.5 million per month. At the high end, $10 million. All gone by April.
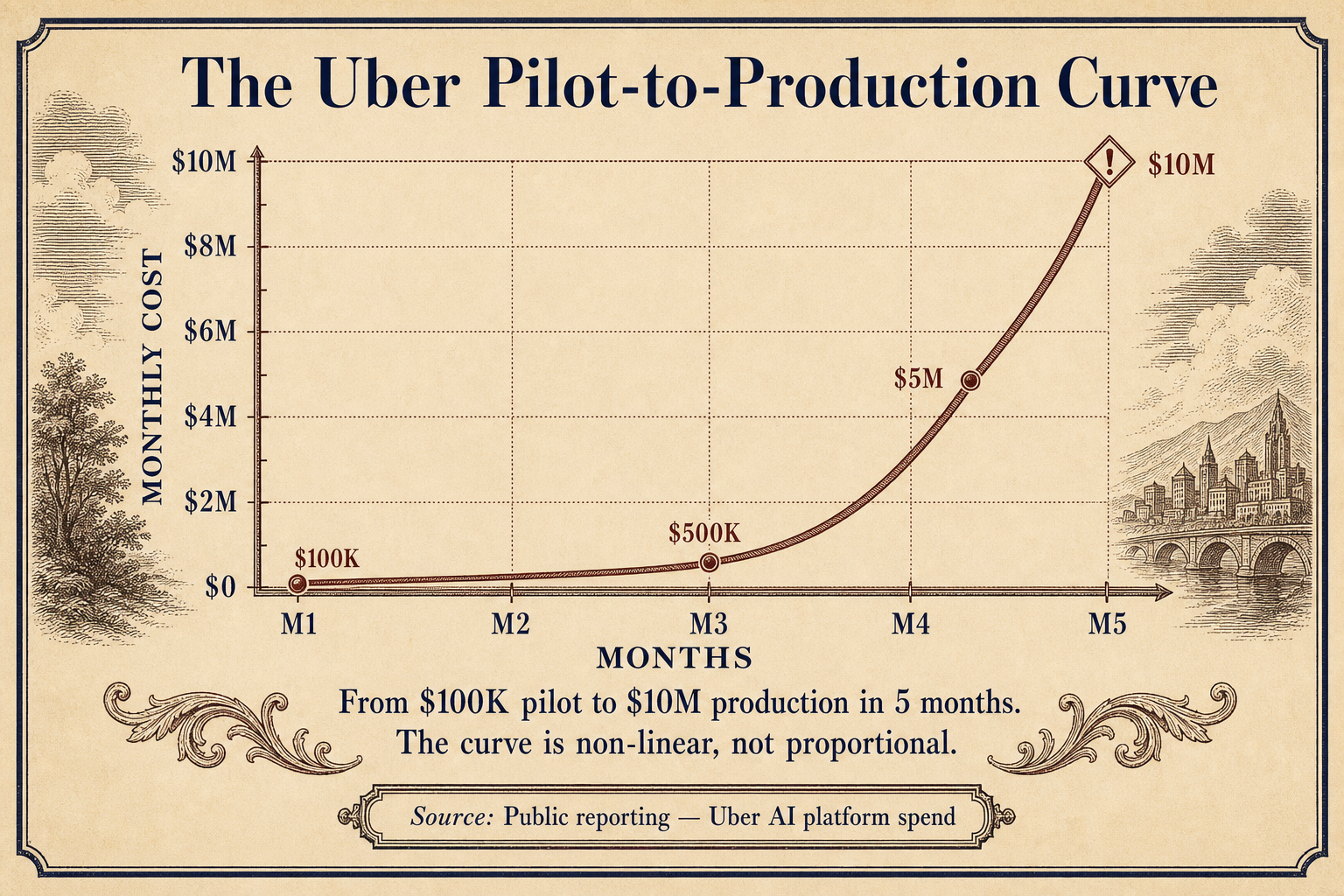
The pilot showed a single engineer getting dramatic productivity gains. The deployment showed 5,000 engineers all running expensive agentic loops simultaneously. No one modeled the concurrency multiplier. No one modeled variance. No one modeled the difference between a demo agent and a production agent.
Uber is not alone. The pattern is repeating at every enterprise that rushed AI adoption without understanding token economics.
The Three Determinants Stanford HAI Identified
Stanford's Institute for Human-Centered AI (HAI) identified three determinants of whether an AI project actually delivers value, as outlined by Stanford HAI:

- Jurisdictional clarity: Does the team understand where the model's authority ends and human judgment begins?
- Task centrality: Is the AI working on the core value-generating task or a peripheral one?
- Task enactment: Does the organization have the operational processes to actually use the output?
Pilots score well on all three because they control the environment. Production fails on all three because the environment is uncontrolled. Jurisdictional boundaries blur. The AI drifts into tasks it was not designed for. The organization does not know what to do with the output.
This is not a technology problem. It is a measurement problem.
The Pairing Metric Problem
Notion's Head of Product Max Schoening called it directly: leadership is mandating AI adoption and creating perverse incentives like token maxing while the actual productivity benefits remain uneven. Token maxing needs a pairing metric, as Schoening explained on Lenny's Podcast.
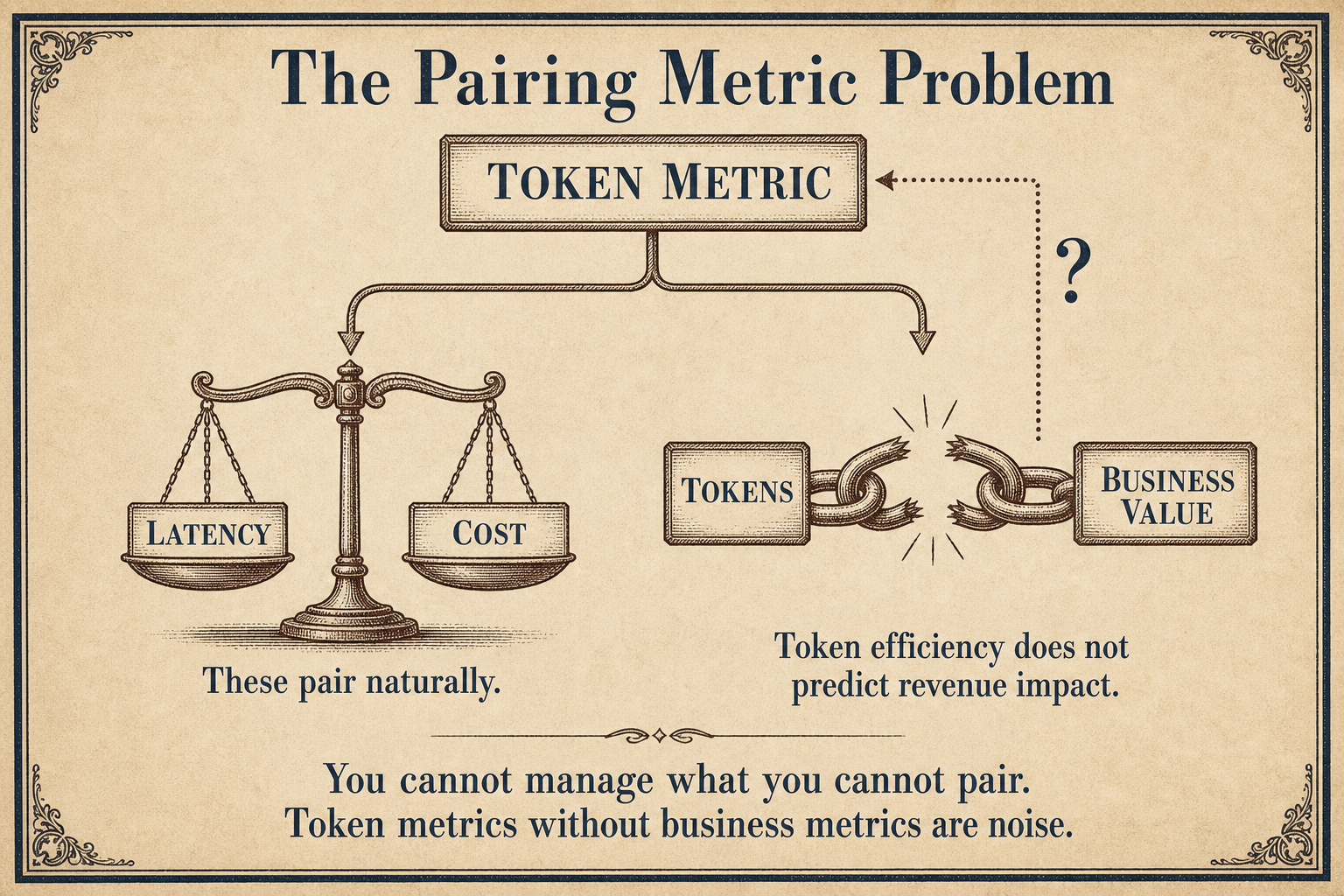
Your pilot tracks cost per conversation. That is a vanity metric. It does not track:
- Cost per resolved issue
- Cost per dollar of revenue generated
- Cost per unit of quality improvement
- Cost per human hour saved
Without a pairing metric, you optimize for the wrong thing. You celebrate lower cost per token while the total cost explodes. You celebrate higher token volume while the output quality plateaus.
A pilot without pairing metrics is not a pilot. It is a sales presentation to yourself.
What Actually Works
The structural gap between pilot and production is addressable. It requires acknowledging that the gap exists and designing for it from day one.

Design for Scale From Day One
Pilots that succeed at production are designed for production scale. They do not use hand-picked queries. They use random samples. They do not use single-turn chat. They use multi-turn agentic loops with realistic failure modes. They do not run for a week. They run for a month with concurrency.
The MIT/BCG finding — 95% of pilots deliver zero impact — reflects a design problem. Organizations treat the pilot as a technical validation when it should be an economic stress test.
Pair Token Metrics With Outcome Metrics
Every token metric needs a business outcome pair. Cost per token paired with revenue per token. Token volume paired with resolved incidents. Agentic loop length paired with task completion rate.
This is not academic. The Stanford paper found that models cannot self-report token costs accurately. You cannot rely on the model to tell you what you are spending. You need independent measurement and pairing at every stage.
Model Routing
Not every query needs a frontier model. Not every task needs a 1,000x agentic loop. Model routing at the inference layer can reduce costs by 5 to 10x per call — roughly 80 percent cost reduction, according to the Token Cost Trap analysis. A simple classification step before the agent loop determines whether the task warrants the full stack or can be handled by a cheaper model.
Pilots never model this because pilots use a single model. Production must use a tiered system.
Caching Architecture
Prompt caching saves approximately 90 percent on reused context, the Token Cost Trap article reports. History summarization compresses long sessions by 70 to 90 percent, preventing exponential growth. Code execution replaces 150,000 tokens of reasoning with 2,000 tokens of execution — a 98.7 percent reduction.
None of these optimizations appear in a pilot budget. They are production engineering. They are the difference between $500 and $847,000.
Understand the Sweet Spot
Toby Ord's curve gives a framework. Before the sweet spot, more tokens deliver more value per token. After it, you are burning money for marginal returns. The pilot should map the curve. Instead, it reports a single point.
Run your pilot at three different scales. Measure cost per unit of output at each. Find the inflection point. Design your production system to sit on the right side of the curve. Most teams run the pilot at 50 conversations and assume the economics hold at 500,000 conversations. They do not. The curve bends.
The Real Cost of the Lie
The enterprise AI pilot is not failing because the technology is bad. It is failing because the economics are fraudulent. The numbers you see in a pilot presentation are not conservative estimates. They are systematically biased toward approval.

The $500 pilot to $847,000 production gap is not an edge case. It is the default behavior of a system that rewards cheap demos and punishes expensive production engineering. The 717x multiplier does not come from increased users. It comes from structural cost multiplication that the pilot design deliberately obscures.
You can close the gap. Model route. Cache aggressively. Pair your metrics. Design for scale from the first line of code. But you have to stop pretending the pilot numbers are real.
They are not real. They are lies. And your budget is the punchline.
Magnus Hedemark writes about AI economics, enterprise strategy, and the gap between what technology promises and what organizations can actually execute. He has an irrational affection for good unit economics and a low tolerance for vanity metrics.