The $1.23 That Reveals Everything

What Revenue-Per-Employee Hides About the Real Economics of AI-Native Companies
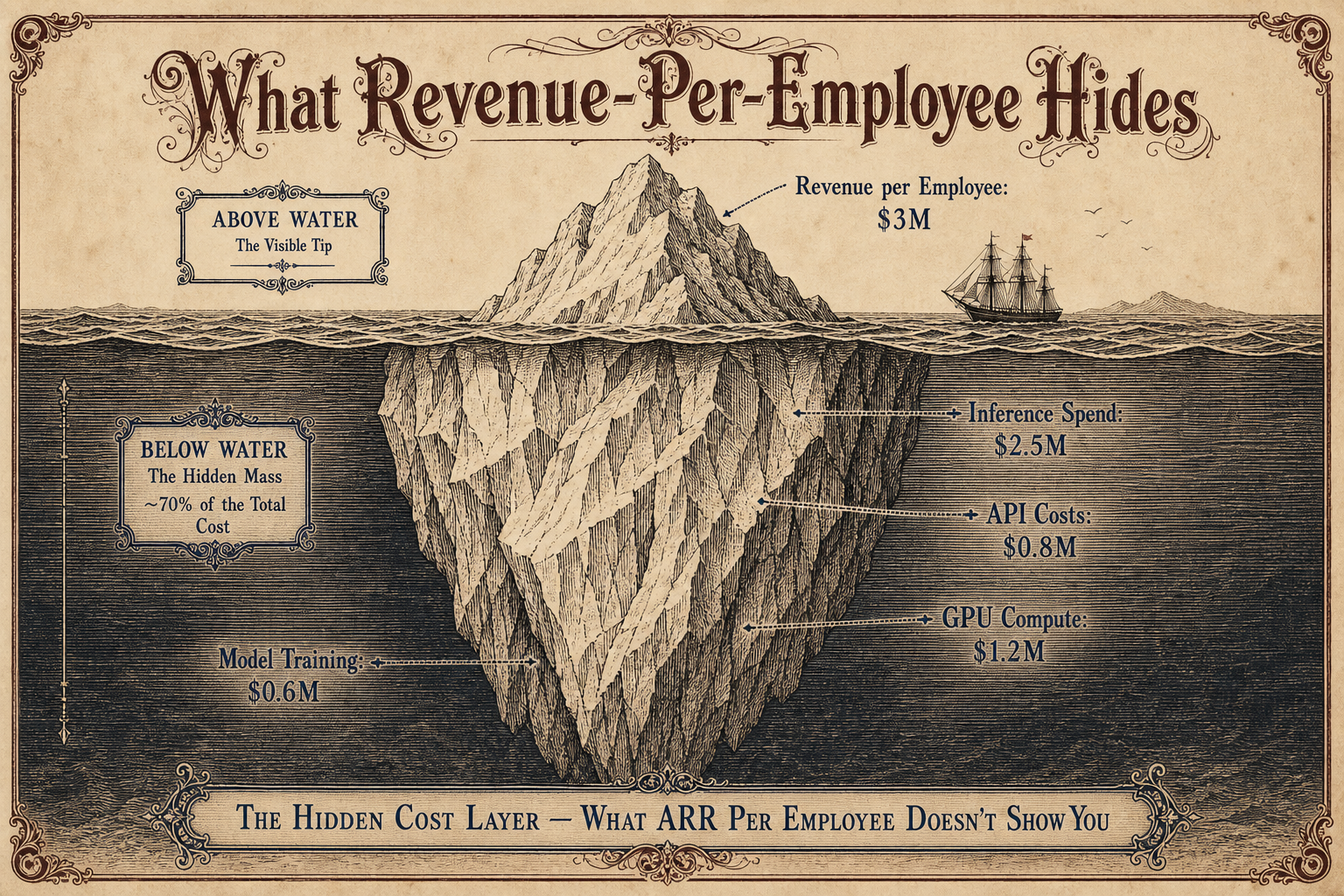
Cursor spent $1.23 on API inference for every $1.00 of revenue at its early stage. Think about that number for a second.
A company burning more on a third-party input than it collects from customers does not look like a business. It looks like a money-burning machine. The press that landed on Cursor's $1B ARR in 24 months, fastest B2B growth in history, and its $3.3M revenue per employee at 300 people told a different story entirely. Magical. Nano-unicorn. The AI margin miracle.
Both stories are true. The disconnect is the point.
Revenue-per-employee is the vanity metric of the AI era. It flatters founders, impresses VCs, and conceals the actual capital allocation strategy that makes nano-unicorns work. When you decompose the unit economics, these companies look less like magic and more like deliberate, ruthless capital allocation choices most organizations are structurally incapable of making.
What $1.23 Actually Means
Cursor hit $1B ARR in 24 months. At peak, its annualized API spend to Anthropic and OpenAI reached $2.5B per year, according to Dealroom data. That means at a $2B revenue run rate, Cursor was paying $2.5B to API providers. Negative gross margin by any traditional definition.
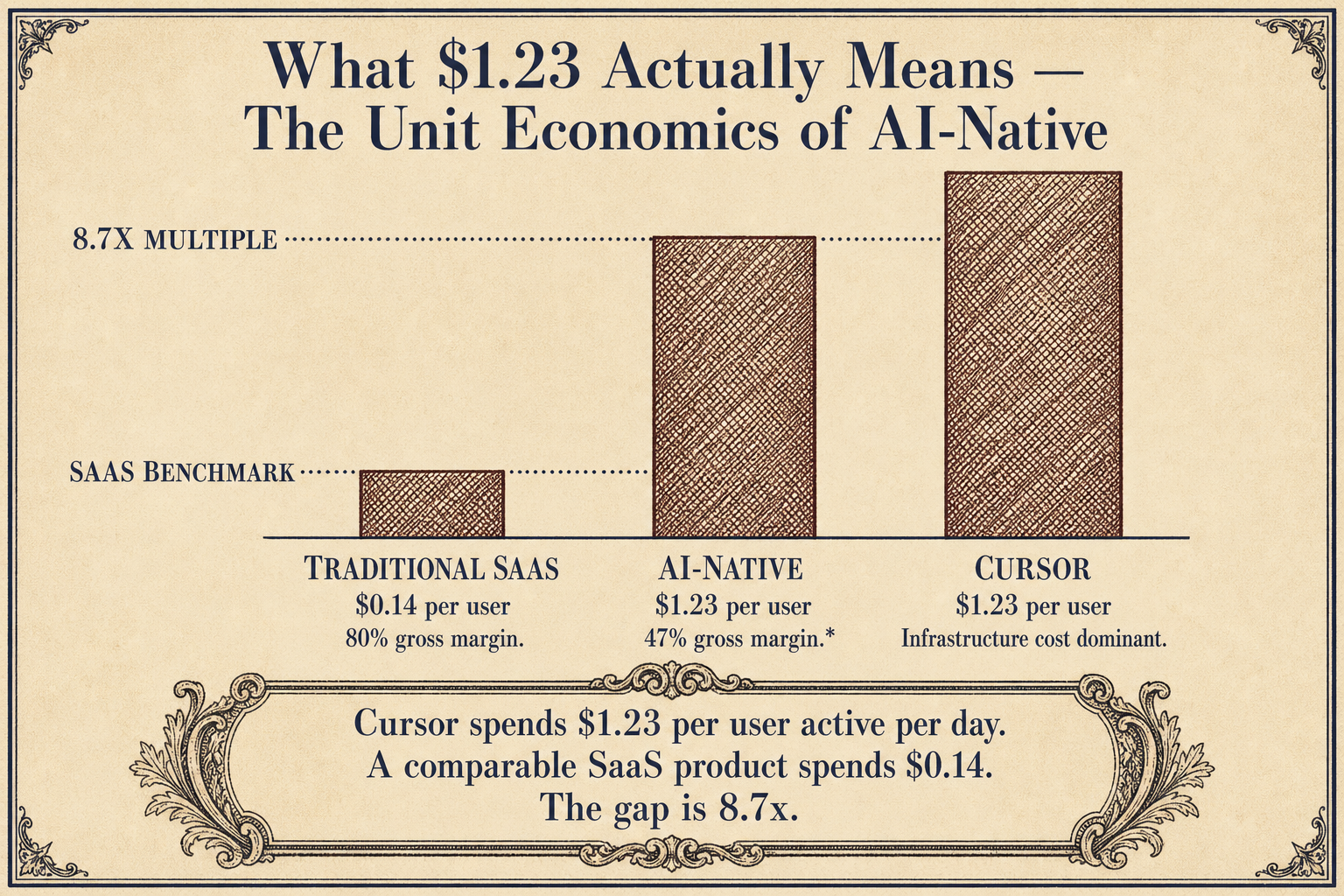
But Cursor wasn't a traditional SaaS company trying to optimize for 80% gross margins. It was a token-maxing machine built on a specific thesis: inference spend is not a COGS (cost of goods sold) problem. It is a growth lever.
Traditional SaaS gross margins sit at 75-80%. S&M spend consumes 30-50% of revenue. CAC payback takes 12-24 months. That model assumes you pay humans to find customers, then deliver software at near-zero marginal cost.
AI-native companies flip the equation. They invert the spend profile. Inference replaces sales calls. Token consumption replaces headcount expansion. CAC payback becomes near-instant because the product sells itself through virality driven by output quality. Gross margins sit temporarily at 40-60%: worse at first glance, better when you realize S&M spend is under 10% of revenue.
The unit economics look worse in the COGS line and better everywhere else. The mistake is stopping at gross margin.
The Three Archetypes
Cursor is the purest example. Zero paid acquisition. Product virality driven entirely by inference quality. Every dollar spent on API calls directly improved the product experience. The $1.23 ratio wasn't a pathology; it was a deliberate choice to prioritize model quality over margin. Cursor later built its own inference model (November 2025) to improve margins, as SaaStr notes. The structure changed once scale justified the vertical integration.

Midjourney proved the model before anyone had a name for it. $500M ARR. Zero VC. Zero marketing spend. $3M to $4.6M revenue per employee, per Sacra. GPU inference is Midjourney's COGS: they run proprietary models on their own hardware. The capital allocation choice is the same as Cursor's: spend on compute, not on people. Midjourney operates with 107-163 people serving millions of users. A traditional media company would need 2,000+ employees to generate $500M in subscription revenue.
Gamma hit $100M ARR with roughly 50 employees and profitability since 2023, according to TechCrunch. Founder Grant Lee says Gamma reached $100M ARR on only $23M in initial funding, per the Gamma blog. The company runs $2M revenue per employee. Traditional SaaS at that scale would have 300-500 people, massive sales teams, and a marketing engine. Gamma has a product that generates presentations with AI, meaning API costs are its primary variable expense.
The Cost Variance That Makes It Work
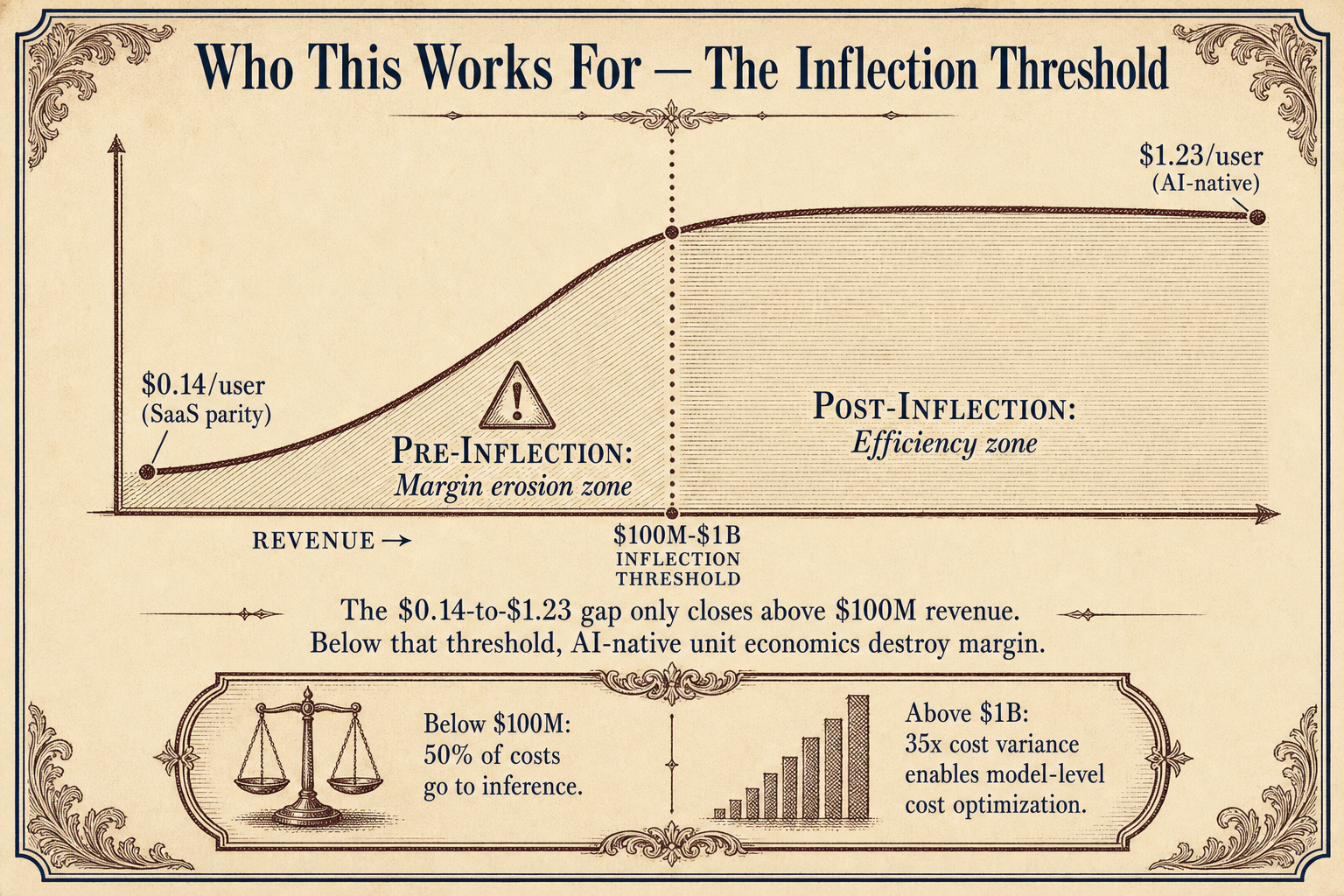
The entire nano-unicorn thesis rests on one hidden variable: the variance between model tiers.
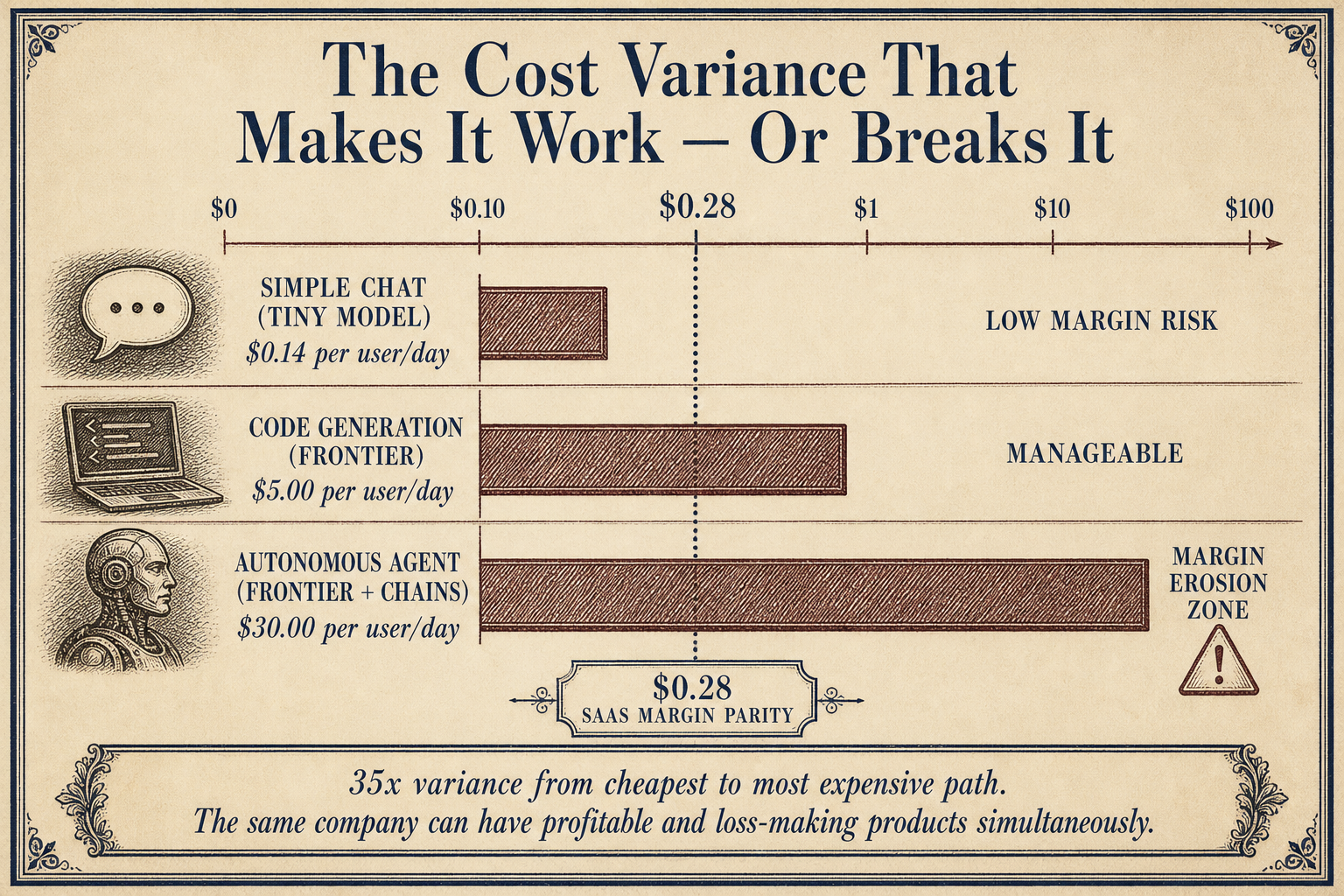
DeepSeek V4 Flash costs $0.14 per million input tokens and $0.28 per million output tokens. GPT-5.5 costs $5 and $30 respectively, according to CloudZero data. That is a 35x to 107x difference between the cheapest frontier model and the most expensive one.
A company building on DeepSeek V4 Flash can spend $23,000 per month and get roughly 82 million input tokens plus 82 million output tokens. That same $23,000 buys about 760,000 input and output tokens on GPT-5.5. The difference is the difference between running a code generation agent that processes hundreds of loops per day versus one that struggles through a few dozen.
The capital allocation choice is not just "spend on inference instead of headcount." It is "choose the right model tier for the right job." The companies that get this right run inference at a fraction of the cost per token that enterprises pay when they default to the most expensive frontier model.
Why Revenue-Per-Employee Lies
Revenue-per-employee is seductive because it implies efficiency. A company with $3M per employee looks like it has discovered organizational magic. Founders want to show this number. VCs love telling this story to LPs.

The ratio hides three things.
First, it conceals the actual capital intensity of AI-native operations. Cursor's $1.23 API cost per $1 revenue means every dollar of claimed "efficiency" was actually subsidized by a massive capital allocation to inference. The revenue-per-employee number is real. The cost structure that generates it is not the one most investors assume.
Second, it ignores that inference spend is itself a form of hiring. When Cursor spends $2.5B on API calls, it is effectively buying labor from Anthropic and OpenAI. That labor shows up as COGS rather than headcount, so it never appears in the revenue-per-employee denominator. The efficiency ratio is real only if you believe API tokens are categorically different from human labor. They are not. They are substitutes with different pricing models.
Third, it masks the temporal mismatch. Early-stage AI companies run negative gross margins intentionally. They burn on inference to build moats. Later, they verticalize: train their own models, negotiate wholesale pricing, optimize routing. The revenue-per-employee number at year one tells you nothing about the margin structure at year three. Most observers compare the wrong periods.
The Capital Allocation Framework
YC General Partner Diana Hu framed this explicitly in her April 2026 Startup School talk: "Founders should be willing to run an uncomfortably high API bill because it replaces what would have taken far more expensive headcount," as recorded in the YC Startup Library.
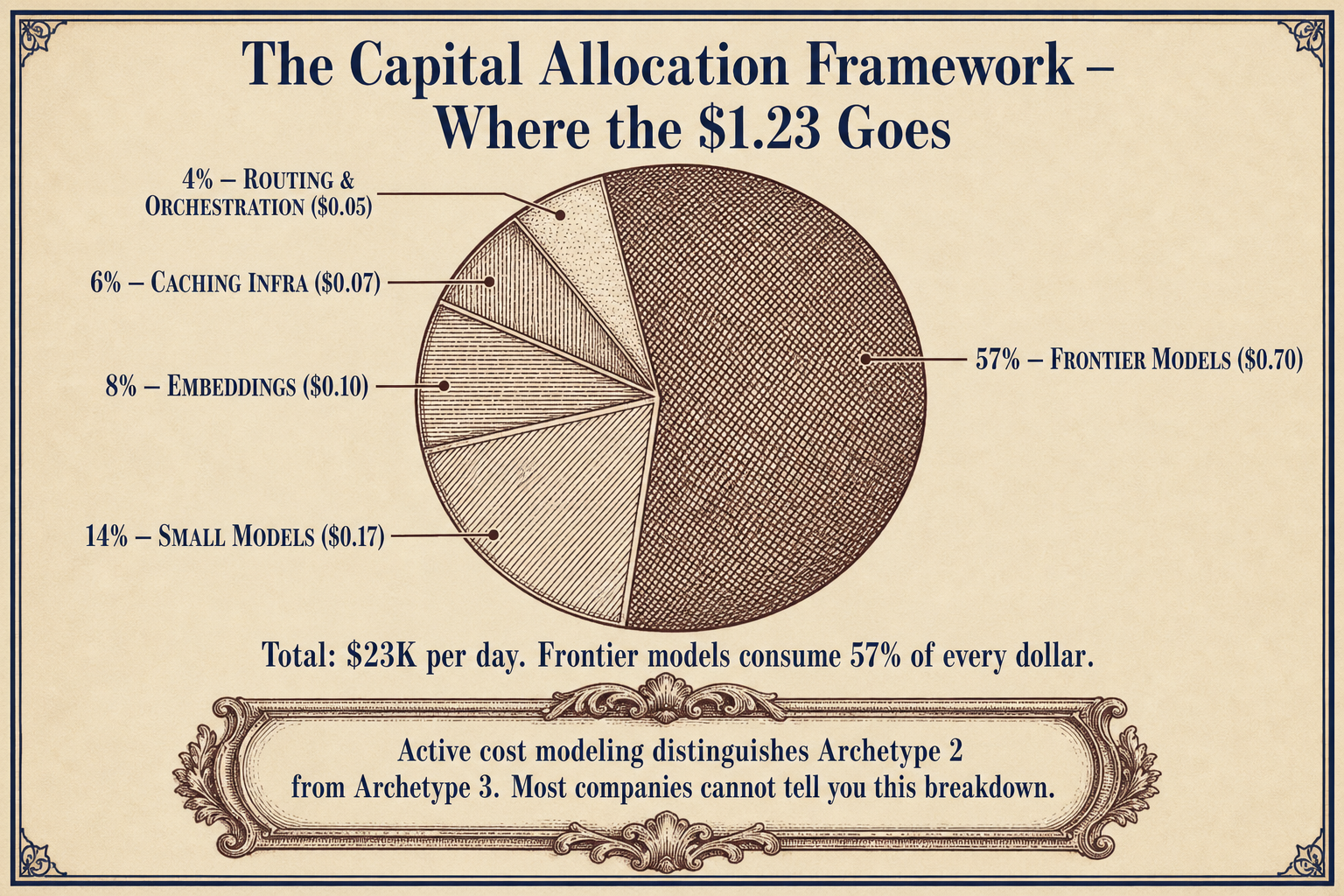
The framework is a direct comparison:
- Human SDR/AE labor: $100K-$130K per year
- AI agent: $10K-$15K basic, $50K-$100K enterprise, according to SaaStr
A mid-level Silicon Valley engineer fully loaded costs $275K-$400K per year. The same money buys millions of tokens per day on DeepSeek V4 Flash. The arithmetic is straightforward: replace variable headcount cost with variable inference cost. Keep the team small. Spend the savings on model calls.
This is not "doing more with less." It is spending the same money on a different input. The leverage is real. It comes from the fact that API tokens scale sublinearly with output complexity while human labor scales linearly with headcount.
Who This Works For
The nano-unicorn model requires specific conditions.
The product must be the AI. Cursor, Midjourney, and Gamma all sell AI output directly. Inference quality is product quality. Spending more on API calls improves the customer experience immediately. This creates a virtuous cycle: better output drives word-of-mouth, which drives revenue, which funds more inference spend.
The growth model must be viral. These companies spend essentially zero on paid acquisition. Product quality IS the marketing channel. Cursor grew from $100M ARR in January 2025 to $1B+ by November 2025 with no sales team. Traditional companies spend 30-50% of revenue on S&M to achieve a fraction of that growth rate.
The cost structure must be compressed on the right side. DeepSeek V4 Flash at $0.14 per million tokens changes the math entirely. A company building on GPT-5.5 at 35x the cost cannot run the same capital allocation playbook. The model tier choice determines whether the unit economics work.
What Companies That Report Revenue-Per-Employee Don't Show You
A company that reports revenue-per-employee without also reporting inference-spend-per-revenue is telling you half the story.

The full metric set for an AI-native company should be:
- Revenue per employee
- Inference spend per dollar of revenue
- Model tier mix (what ratio of calls hits cheap vs expensive models)
- Token utilization rate (what percentage of tokens consumed produce customer-facing output)
- Gross margin trend (is the margin improving as the company verticalizes?)
Cursor at $1.23 per dollar of revenue looks bad on the second metric. But Cursor at $1B ARR with near-zero S&M spend and product virality that no traditional company can replicate looks extraordinary on the full set.
Midjourney at $3M+ revenue per employee with zero API spend to a third party (they run their own hardware) looks like a different animal entirely. The inference spend is internalized. The capital allocation is the same: spend on compute, not headcount, but the accounting treatment flatters the revenue-per-employee ratio even more.
The Real Lesson
The nano-unicorn story is not about the magic of AI making humans obsolete. It is about capital allocation. These companies identified that inference spend generates higher marginal returns than S&M spend or headcount growth. They chose inference.

That choice is available to any company. Most cannot make it because their organizational structure, investor expectations, and accounting frameworks are built for the old model. Gross margin targets. Headcount budgets. S&M quotas.
The companies winning in AI-native markets are the ones that recognize revenue-per-employee as a vanity metric and replace it with the real question: what is the marginal return on a dollar of inference spend versus a dollar of human labor?
For Cursor early on, the answer was $1.23 of API cost per $1 of revenue, and that was the best bet on the table.
Sources inline throughout.