The Dark Factory Is Already Shipping

Three Engineers, No Human Code Review, $1,000/Day in Tokens -- The Enabling Techniques Matter More Than the AI
Three engineers. One thousand dollars per day each in LLM tokens. Zero human code review. StrongDM's Level 5 Dark Factory is already shipping production code to real customers with no human touching the implementation. The AI lab inside StrongDM, founded July 2025, runs a software factory where humans write specs and agents write everything else. The factory has produced Attractor (an open-source coding orchestration layer), CXDB (16,000-plus lines of Rust, Go, and TypeScript), and StrongDM ID, a production identity platform with SSO and multi-IDP support. Every line was generated and validated by agents without human review, as documented on the StrongDM Software Factory blog, the StrongDM Factory Docs, and the Attractor GitHub repository.
The AI hype cycle wants you to focus on the models. GPT-5. Claude Opus 4. DeepSeek V4. Those headlines miss the point. The architectural leverage in a software factory comes from four enabling techniques that surround the model, not from the model itself. Digital Twin Universe. Probabilistic satisfaction. Scenario holdouts. Specs as code. These four design decisions determine whether an AI factory produces shippable software or expensive spaghetti.
The DTU Changes Everything About Validation
StrongDM's Digital Twin Universe is an in-memory collection of behavioral clones for every third-party service the factory depends on. Okta, Jira, Slack, Google Docs, Drive, Sheets -- the DTU replicates their APIs, their edge cases, and their observable behaviors, as described in the DTU documentation.
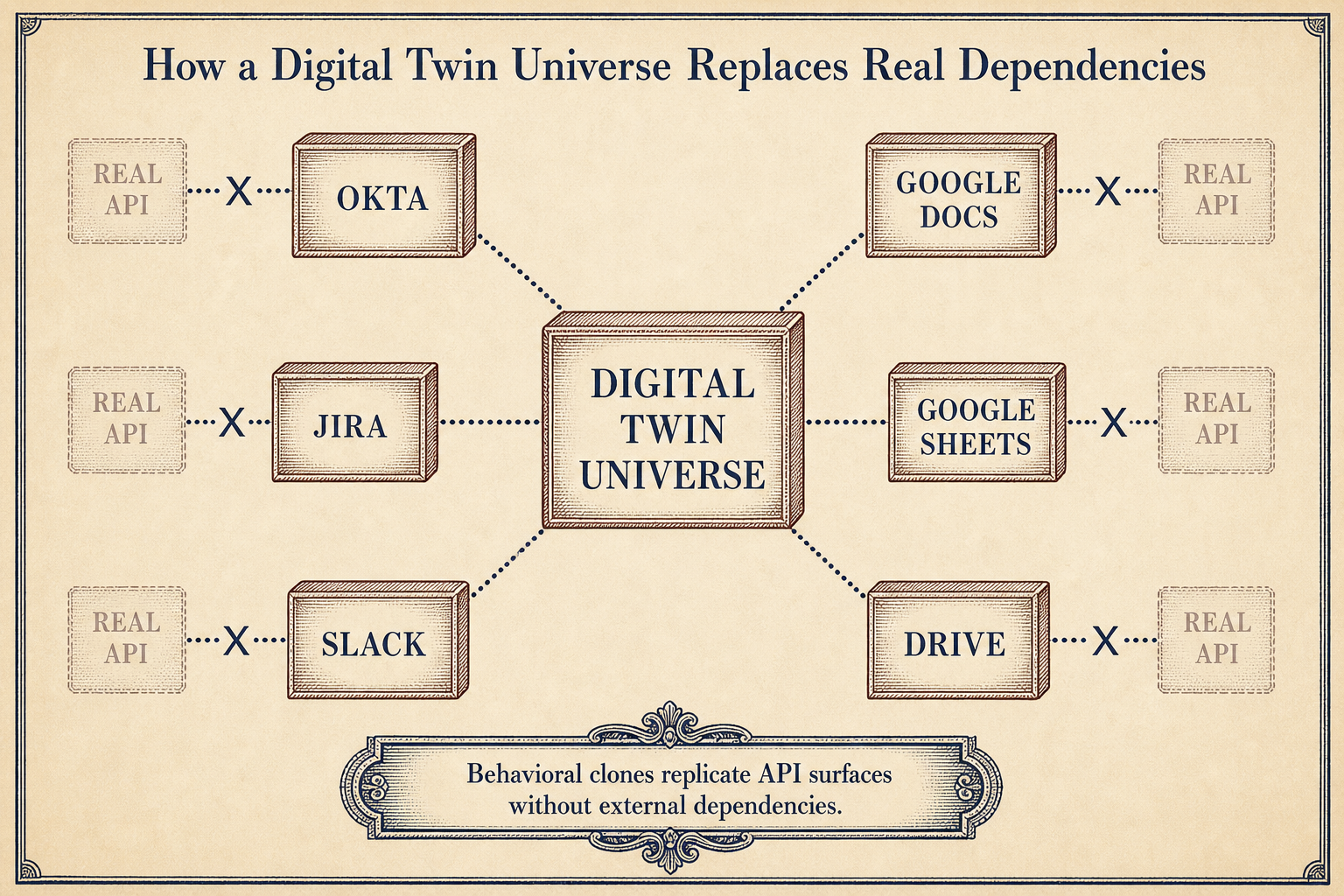
Why this matters: a software factory that validates against production APIs is a factory that validates slowly and expensively. Production APIs rate-limit you. Production APIs cost money per call. Production APIs have side effects you cannot undo. The DTU eliminates all three constraints. The factory runs thousands of scenarios per hour against simulated services that behave indistinguishably from the real thing. No rate limits. No API costs. No accidental Slack messages to real users.
This is the architectural insight that enables everything else. Without a DTU, you cannot run enough test volume to trust probabilistic satisfaction. Without enough test volume, you cannot remove human review. The DTU is the load-bearing wall of the entire Dark Factory architecture.
Probabilistic Satisfaction Is a Deeper Change Than Code Generation
Traditional software engineering uses boolean test results. Tests pass or they fail. A red build blocks merging. A green build clears it. This binary gate works when humans write tests and humans write code. It breaks when agents write both.

StrongDM replaces boolean pass/fail with probabilistic satisfaction metrics: the fraction of successful user trajectories across all defined scenarios. A version ships when its satisfaction score clears a pre-defined threshold, not when every assertion returns true, according to StrongDM's factory quality gates documentation.
This shift from discrete to continuous validation is philosophically important. Boolean testing assumes you can enumerate correctness. Probabilistic satisfaction accepts that correctness is a spectrum. An agent-generated system that scores 94 percent across 10,000 scenario trajectories is more trustworthy than a human-written system that passes 200 unit tests. The first has been exercised at scale against realistic behavior. The second has been checked against programmer assumptions.
The technique also enables graceful degradation. When a new agent iteration scores 91 percent instead of 93 percent, the factory can compare the delta, trace the regression to specific scenarios, and feed that signal back into the next generation cycle. Boolean pass/fail cannot give you that. You get red or green and nothing in between.
Scenario Holdouts Prevent the Agent From Cheating
Here is the problem every AI coding system faces: agents are good at pattern-matching on their training data. If the test scenarios live inside the codebase, the agent can learn to write code that passes those specific tests without understanding the underlying problem. This is overfitting applied to software generation.
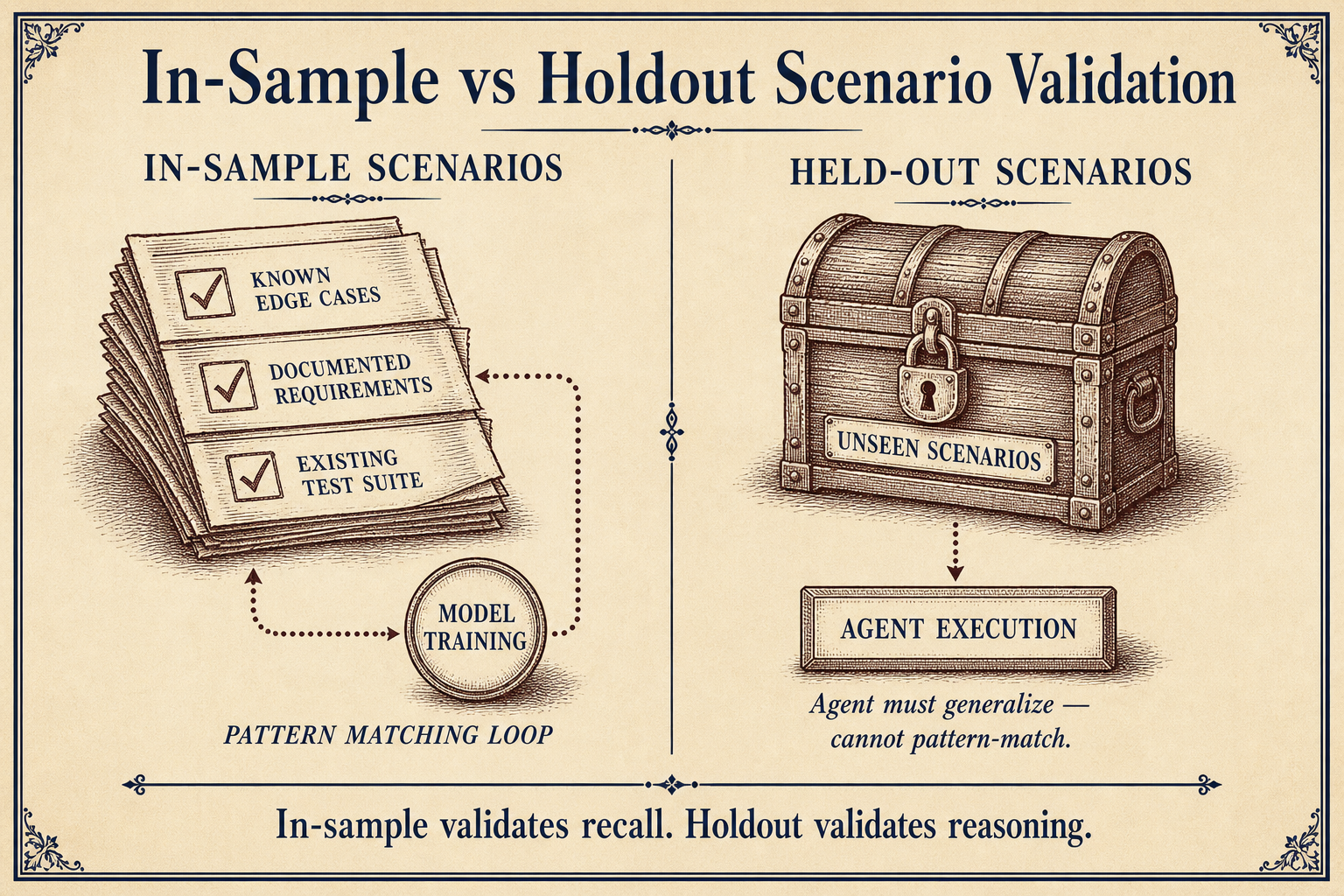
StrongDM stores end-to-end user stories and scenario definitions outside the codebase. The agent cannot read them. The agent cannot optimize for them. The agent must write code that satisfies constraints it has never seen, as explained in StrongDM's factory technique documentation.
This is the same principle that separates legitimate machine learning from data leakage. Holdout sets are standard practice in model evaluation. StrongDM applied the same logic to code generation. The scenario holdout is the factory's equivalent of a held-out test set. It prevents the generation process from gaming the validation process.
The consequence is significant: the agent must actually produce correct, generalizable code rather than code that matches a known answer key. This is the difference between a student who memorizes the test bank and a student who understands the subject.
Specs as Code Changes Who Programs
The software factory pattern replaces programming with specification. Humans write NLSpec documents -- structured natural language descriptions of what the system should do, along with constraints, edge cases, and success criteria. The factory compiles those specs into code, as shown in the Attractor llms.txt spec on GitHub.
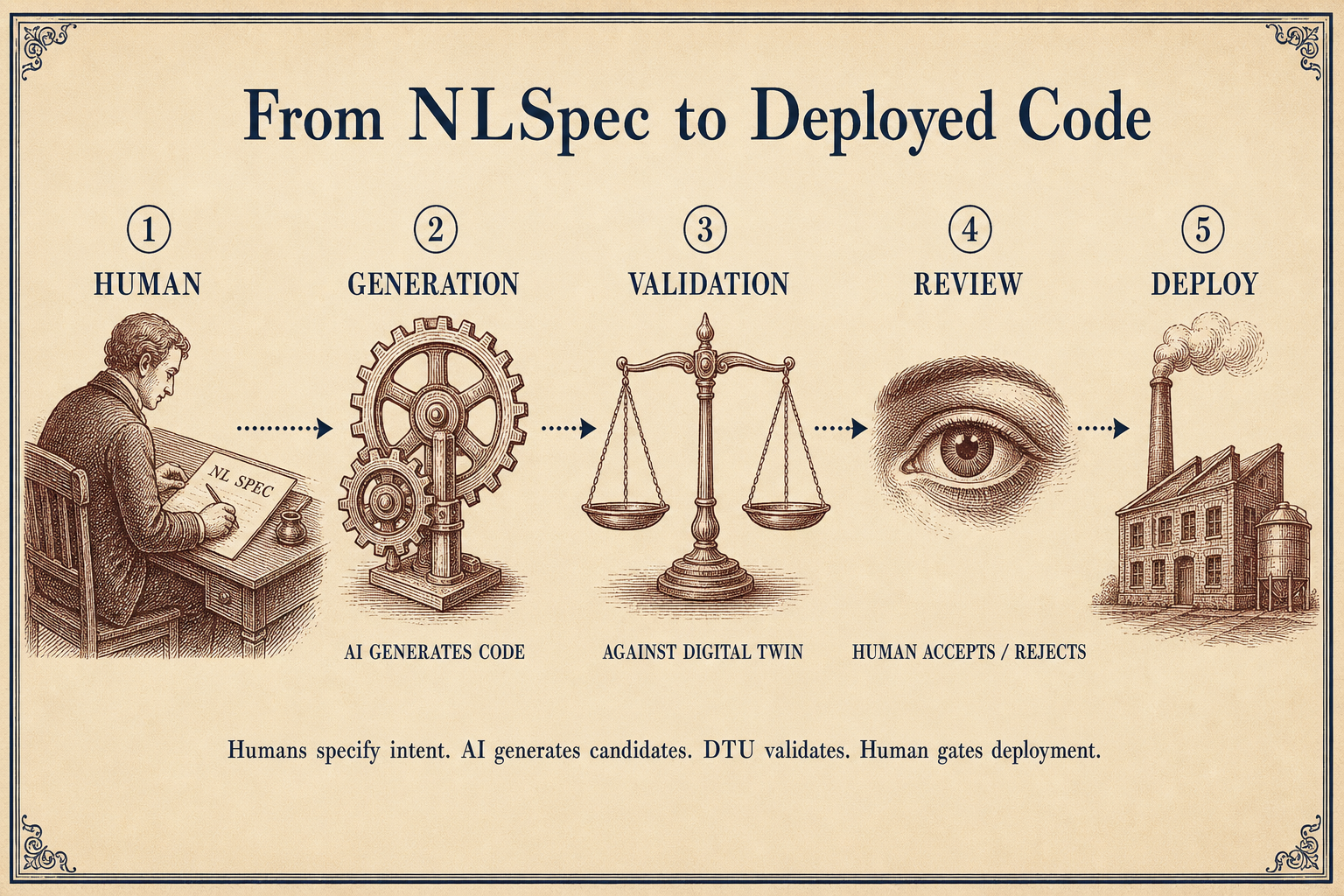
This is not prompt engineering. Prompt engineering is a conversation where the human guides the model step by step. Spec compilation is declarative. You describe the destination. The factory finds the path. The distinction matters because it changes the bottleneck. Prompt engineering bottlenecks on the human's ability to craft good prompts. Spec compilation bottlenecks on the human's ability to define correct requirements.
Diana Hu of YC described the same shift at YC Startup School in April 2026: "Humans write a spec and a set of tests that define success. AI agents generate the implementation and iterate until tests pass," as noted in the YC Playbook.
The deeper point is that specs as code changes who can participate in software production. If writing code is the requirement, you need engineers. If writing specs is the requirement, you need domain experts who understand the problem. Those are often different people. The factory lets domain experts drive development directly.
Stripe Minions Show the Difference Autonomy Makes
Stripe's Minion system ships 1,300 pull requests per week with zero human-written code. That is an impressive number. But Stripe operates at Level 2 to Level 3 on the MindStudio autonomy framework. Every Minion-generated PR is still reviewed by a human before merging, as detailed on the Stripe Minions blog, covered by InfoQ, and broken down by ByteByteGo.
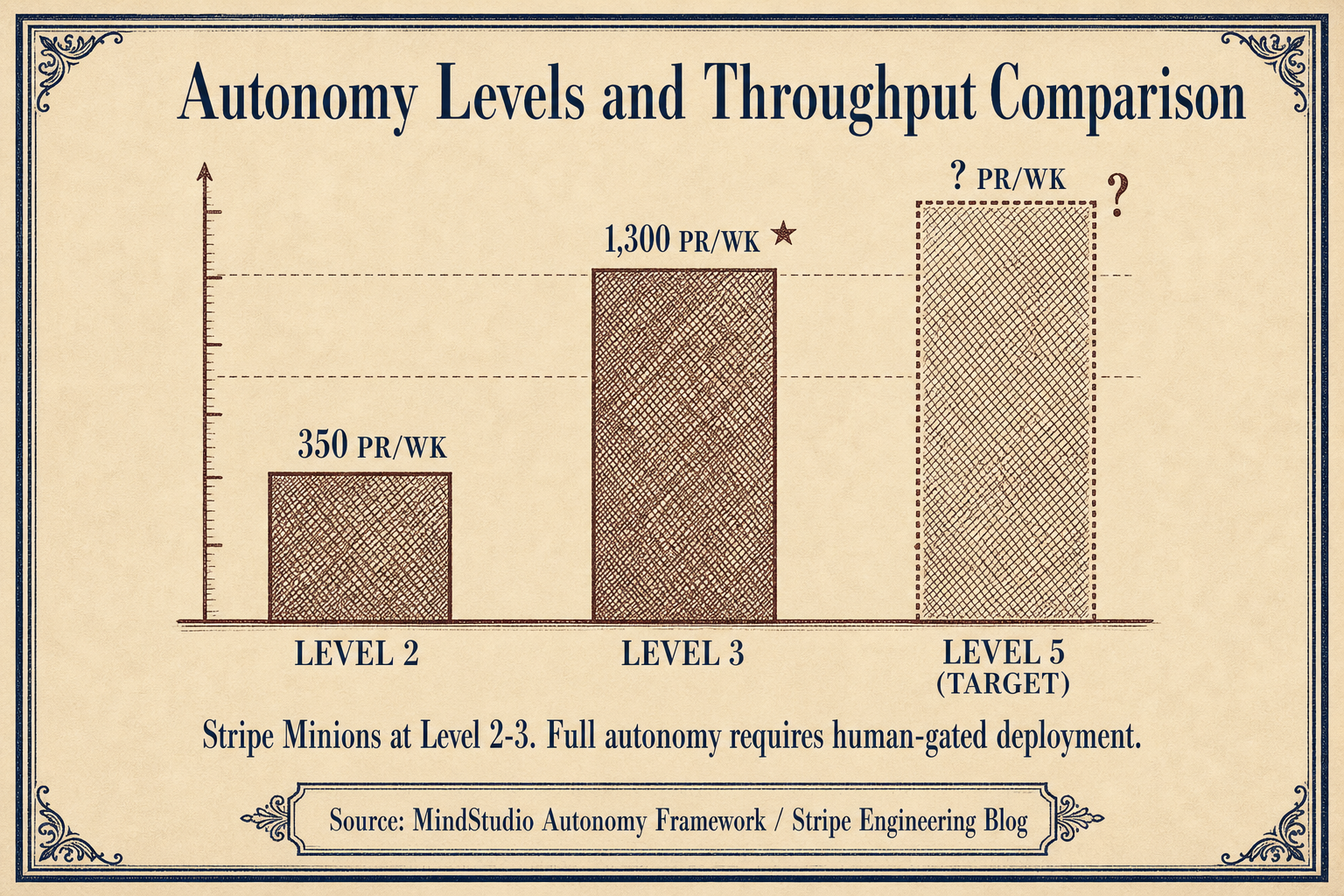
StrongDM operates at Level 5. The difference is not in generation quality. Both systems use frontier models. The difference is in the validation architecture. Stripe uses one-shot generation followed by human review. StrongDM uses iterative generation against a DTU with probabilistic satisfaction thresholds and scenario holdouts.
The five levels of AI coding autonomy, as defined by MindStudio, are:
- Level 1: AI-Assisted -- human drives everything, AI is faster keyboard
- Level 2: AI-Generated + Human Review -- AI drafts, human approves every PR
- Level 3: AI-Generated + Automated Gates -- AI writes, tests review, humans on failures
- Level 4: Mostly Autonomous + Escalation -- AI handles full loop, humans on novel issues
- Level 5: Full Dark Factory -- AI runs end-to-end, humans define goals only
This five-level framework is defined by MindStudio.
Most organizations claiming "AI-generated code" are at Level 2 or Level 3. They have not removed the human from the validation loop. They have only accelerated the human. StrongDM removed the human. That required the four enabling techniques.
The Economic Numbers Support the Thesis
Three engineers burning $1,000 per day each on tokens. That is $3,000 per day operating cost for the factory. At that burn rate, the factory can run tens of thousands of generation-and-validation cycles per day. The cost per generated function is pennies. The cost per validated, shippable feature is still well below traditional engineering cost because the alternative is hiring 30 engineers instead of three.

Steve Yegge recently wrote that code now has less than one year of shelf life. When code is throwaway, the economics of human-written code collapse. You cannot justify a six-month development cycle for code that will be replaced in 12 months. The factory economics invert the traditional trade-off. High token burn with zero human labor cost beats low token burn with expensive human labor cost when the output has a short half-life.
Three Open Questions the Industry Has Not Answered
First, security validation in probabilistic systems. If you cannot guarantee that a piece of code passes all security tests -- only that it satisfies a probabilistic threshold -- how do you certify it for regulated environments? Boolean gates exist for a reason in compliance-heavy industries. Probabilistic satisfaction may not map cleanly onto SOC 2 or FedRAMP requirements.

Second, the relationship between scenario coverage and trustworthiness. At what scenario count does probabilistic satisfaction become as reliable as human review? One thousand scenarios? Ten thousand? One hundred thousand? The factory can generate scenarios in the DTU, but the DTU is itself a simulation. Edge cases the DTU does not model are edge cases the factory will miss.
Third, the shift from prompt engineering to spec compilation requires a new engineering discipline. Current software engineers are trained to write code. Spec compilation requires writing precise, testable, unambiguous NLSpec documents. That is a different skill. The organizations that excel at software factories may not be the ones with the best AI infrastructure. They will be the ones with the best spec writers.
Academic research supports the direction. Terragni et al. (2024) describe the growing symbiosis between human developers and AI, highlighting integration challenges that spec compilation addresses. Kessel and Atkinson (2024) argue that current code models have a major weakness: they are trained only on syntactic facets, not semantic understanding of runtime behavior. Software factories, with their validation loop against behavioral DTUs, directly address this gap. The model generates syntax. The validation loop verifies semantics.
The Factory Architecture Is the Moat
The model providers are racing to commoditize intelligence. GPT-5, Claude Opus 4, DeepSeek V4, Gemini 3 -- each generation erases the advantage of the previous one. If your AI coding system is just "call a good model and hope," you have no durable advantage. Your stack is one API price cut away from irrelevance.
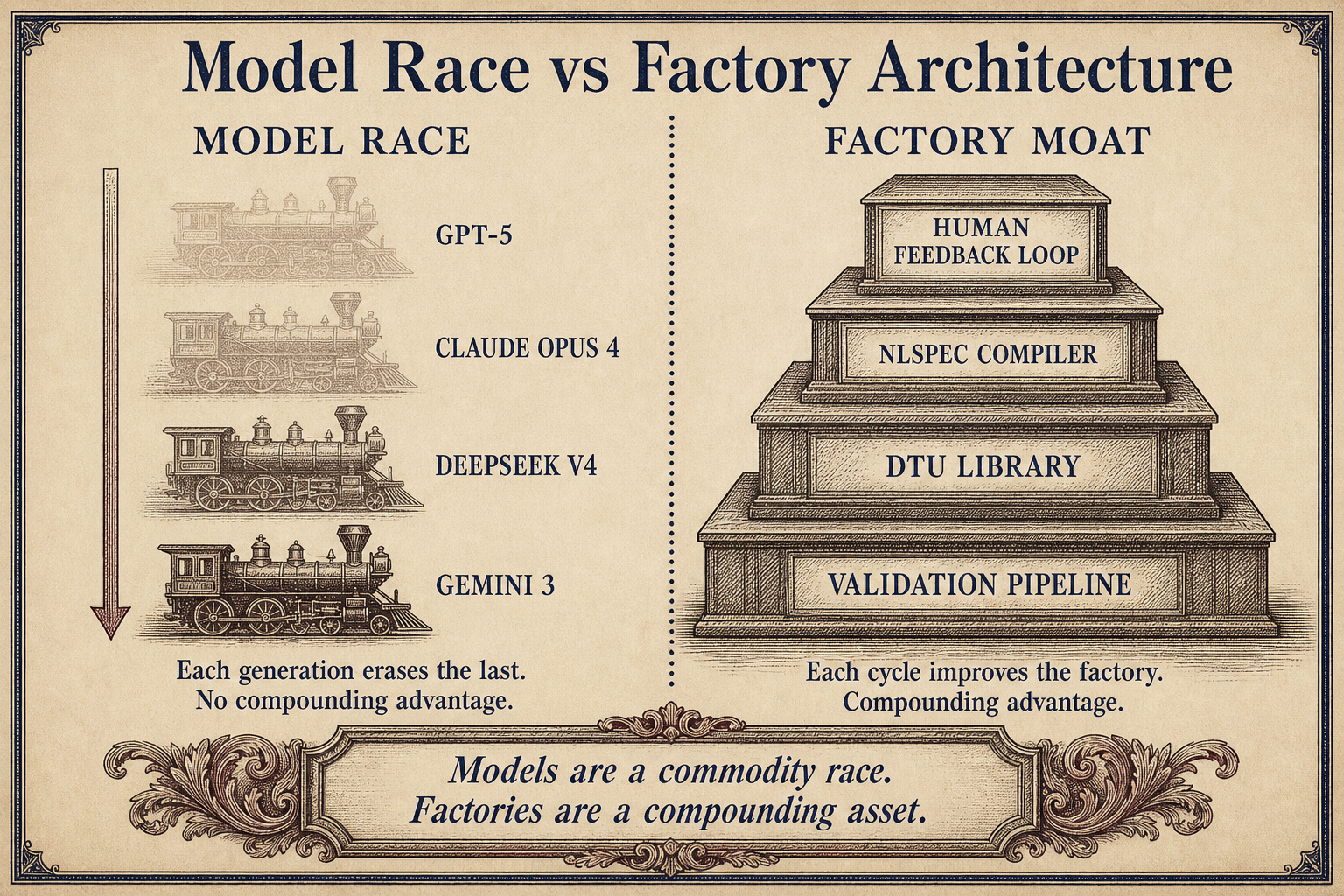
StrongDM's moat is not the model. It is the factory: the DTU that enables high-volume validation, the probabilistic satisfaction framework that replaces boolean gates, the scenario holdout system that prevents agent cheating, and the spec compiler that decouples intent from implementation. These four techniques are harder to replicate than any model call. They require deep understanding of your domain, your validation requirements, and your deployment constraints.
The Dark Factory is already shipping. Three engineers, no human review, real production code. The AI is the engine. The techniques are the chassis. The chassis is what matters.
Magnus Hedemark writes about the intersection of software engineering and AI infrastructure. He is a staff engineer at [organization]. The views expressed are his own.