The Artifact Pyramid: Progressive Disclosure for What Agents Produce

My work on the Groktopus newsletter is research-intensive. Every article starts with papers, industry analyses, technical documentation, and competing product claims. I was feeding all of that into my AI-assisted research workflow, loading the full context of every source into every session. My inference bills climbed. Not dramatically at first, but steadily, month over month.
Then I noticed something worse than the cost. The quality was degrading. When I loaded a 40-page research report into context alongside a specific question about competitive positioning, the model had to wade through methodology sections and raw data tables to find the relevant analysis. The same inverted-U failure pattern that progressive disclosure solves on the input side was alive and well on the output side. The more context I gave the model, the worse it performed on the specific question I actually needed answered.
I solved this problem for myself by changing how I structure research outputs. Instead of a single flat artifact that bundled everything together for every consumer, I started organizing findings into layered, progressively-disclosable units. A single-page summary with key findings. A collection of analysis files, each self-contained. A set of supporting dossiers for anyone who needs to verify a claim or go deeper. Each layer links down to the next, so a consumer (whether human or agent) navigates to exactly the depth they need and stops there.
Progressive disclosure is a first principle of agentic AI design. It governs how agents consume knowledge: load only what's needed at startup, pull in detail on demand. That same principle has a mirror. It applies to what agents produce. I think this pattern, the artifact pyramid, is broadly useful for anyone doing research with AI today. So I want to introduce it here, grounded in the first principles that make it work, and invite the community to consider adopting it.
agentskills.io specification codifies this principle into a three-tier model. Claude Code, Hermes Agent, GitHub Copilot, and OpenAI Codex all implement some version of progressive skill loading. An agent carries a map, not the entire territory. The artifact pyramid applies this same discipline to what agents produce.
The Artifact Pyramid
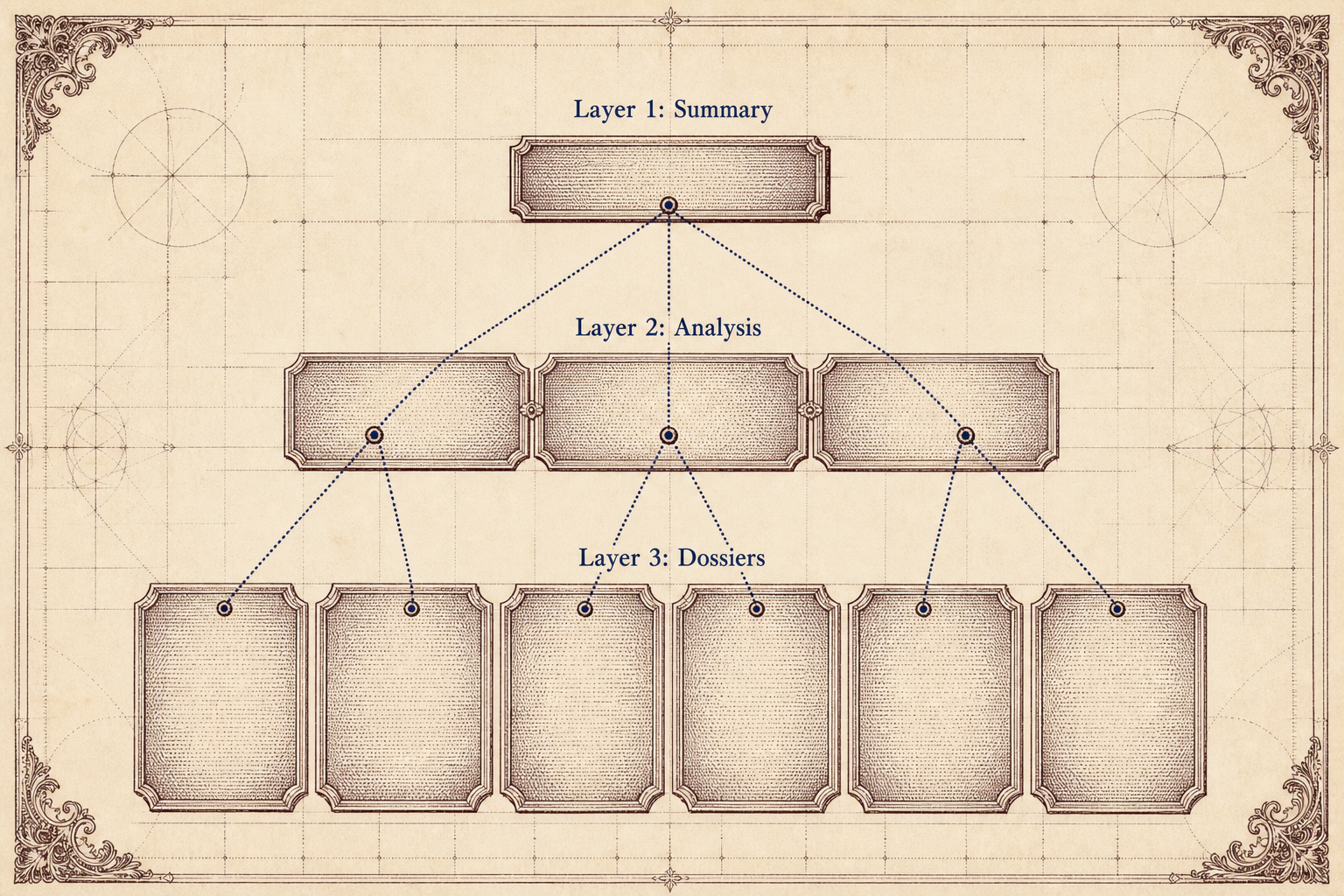
The artifact pyramid is a structured research output organized into three layers of increasing depth. Each layer links down to the next with a clear description of what a deeper consumer will find.
Layer 1 is the summary. A single file, typically a few paragraphs to a few pages. It states the research question, the key findings, and the most important implications. It doesn't include evidence, methodology, or supporting data. Those live one layer down. Every claim in the summary links to the analysis file that substantiates it. A product-manager agent reads this layer and nothing else, coming away with everything it needs for strategic decision-making.
Layer 2 is the analysis collection. A set of individual files, each covering a specific dimension of the research: market analysis, competitive landscape, technical feasibility, risk assessment. Each analysis file is self-contained enough to stand alone. A data-scientist agent who only needs the data organization analysis loads that single file and nothing else. Each analysis file links down to the Layer 3 files that contain its supporting evidence.
Layer 3 is the detailed dossiers. The broadest layer, potentially containing many files: source excerpts, raw data tables, interview transcripts, methodology notes. These aren't intended to be read linearly. They are a reference library that consuming agents pull from as needed.
The architectural logic is the same three-tier model the agentskills.io specification defines for skill loading. At the skill level, metadata (name and description) loads at startup, full instructions load on invocation, and reference files load on demand. At the artifact level, the summary is the metadata, the analysis files are the full instructions, and the dossiers are the reference files. The same progressive disclosure discipline that makes a library of fifty skills economical, roughly 2,500 tokens of overhead at startup instead of 50,000, makes a research output with three layers of depth economical for a fleet of consuming agents.
How It Serves Multi-Agent Consumption
Multi-agent architectures amplify the context economy problem dramatically. Each agent in a pipeline inherits context from upstream agents. Without careful design, context accumulates across stages until every downstream agent operates in a window polluted by material irrelevant to its specific role.
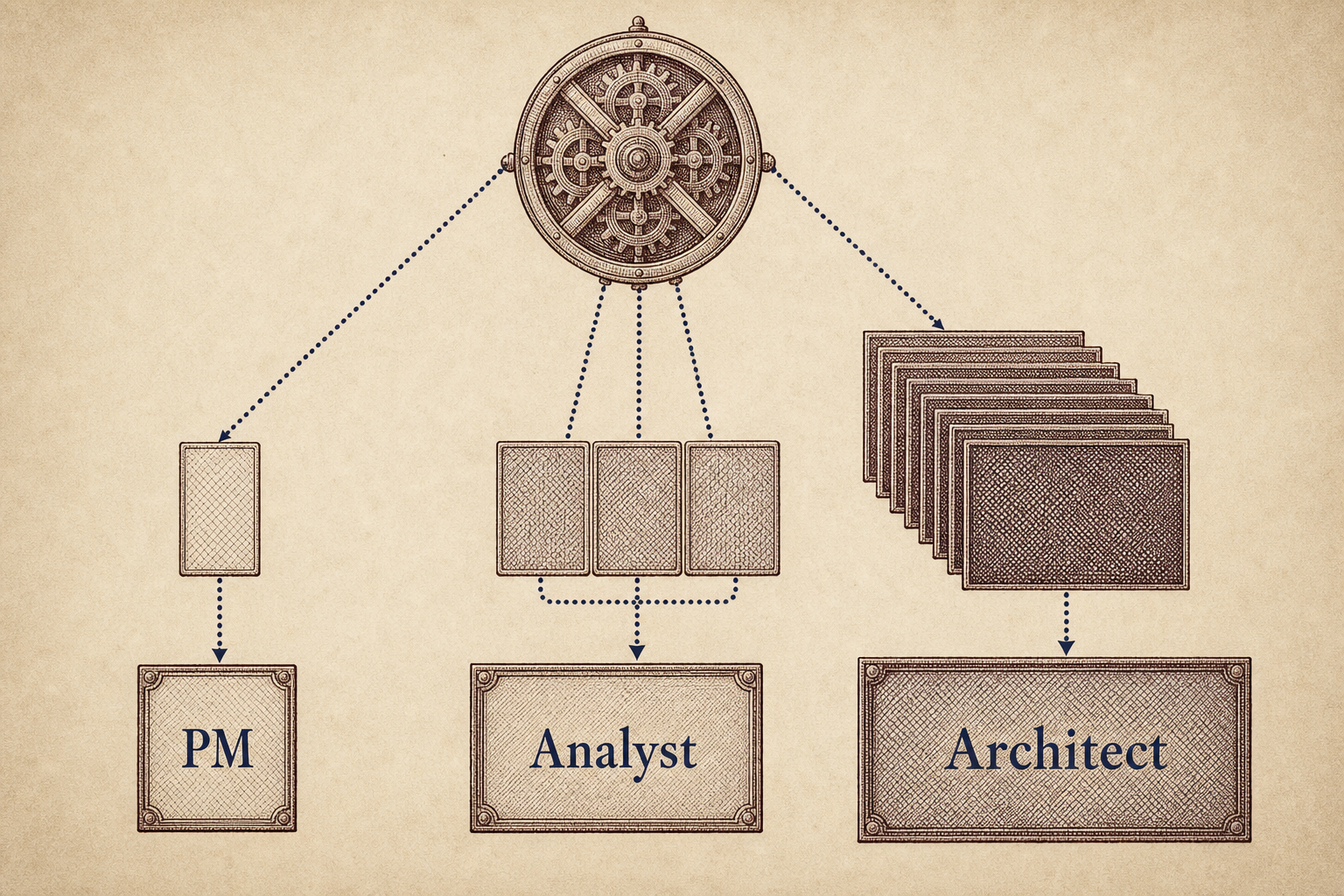
The artifact pyramid gives the orchestrator the precision to deliver only what each downstream profile requires. A product-manager agent reads only the Layer 1 summary, gaining strategic orientation without paying for technical depth. A market analyst reads specific Layer 2 files relevant to its domain, pulling from the analysis collection without loading the full dossier layer. A data architect reads Layer 3 dossiers, descending to raw data organization considerations that no other profile needs.
The practical mechanism is straightforward. Each file at every layer carries, at the top or bottom, an explicit sources section with absolute path references and descriptions:
research/analysis/market-position.md-> Competitor mapping and market share analysis supporting Section 2
research/analysis/technical-feasibility.md-> Architecture evaluation supporting Section 3
research/dossiers/competitor-profiles.md-> Raw competitor data dossiers
These aren't footnotes. They are navigation affordances for agent consumers. Each description answers the question the consuming agent asks before loading: *what will I find if I go deeper?*
How the Pyramid Gets Built
The pyramid isn't a formatting template applied after research is complete. It is the natural output of a recursive research methodology where the researcher evaluates gaps and decides how deep to go.
It begins with a mission brief from an orchestrator. The first step is *mission interpolation*: reformulating the brief into explicit research questions, scope boundaries, and a register of known unknowns. The researcher must understand the orchestrator's intent well enough to predict which layers different downstream consumers will need. This is itself a knowledge operation, and it's what separates the artifact pyramid from a flat report.
The researcher then runs a systematic gathering pass using tools like GroktoCrawl, an open source, self-hosted web scraping and AI research stack that supports search, scrape, crawl, and agent-driven research across multiple sources. After structuring what was found into preliminary pyramid layers, the researcher evaluates gaps against three criteria: is this gap in-scope per the mission brief? Would filling it change any conclusion in the layers above? Does it add depth or just bulk? This gap evaluation model, borrowed from qualitative research's saturation logic, determines whether another recursion round is warranted.
The key insight is that the researcher determines how many layers are warranted based on mission complexity, not a fixed template. A simple technology explanation brief may produce only a summary and two analysis files. A competitive landscape analysis may require all three layers plus multiple files per layer. The pyramid's depth is a function of the research's actual information density. This mirrors how the agentskills.io standard lets skills determine their own complexity: a simple one-step skill is a single file, while a complex skill uses the full directory structure with references, scripts, and templates.
The Symmetry That Matters
Progressive disclosure as a design principle has deep roots in human-computer interaction: the idea that revealing complexity incrementally rather than all at once produces better outcomes than exposing everything simultaneously. Ardalis formalizes this for the AI agent context: "Instead of bombarding an audience with everything they might ever need to know, you give them just enough to act now, with clear pathways to more detail as it becomes relevant. The agent carries a map, not the entire territory."
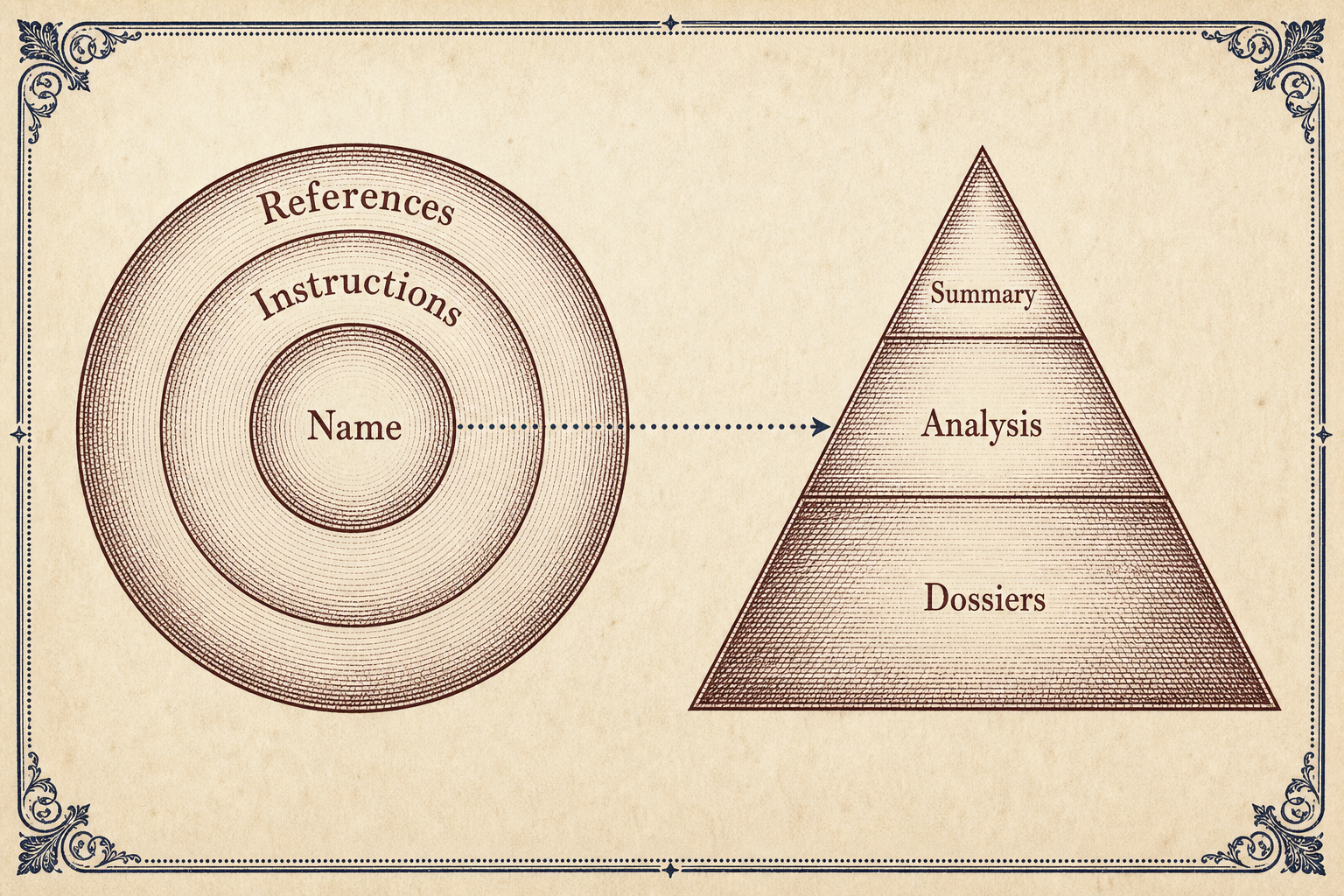
The artifact pyramid extends this from a consumption-side principle to a production-side practice. When the researcher produces artifacts that respect progressive disclosure, every consuming agent downstream inherits the benefit of that design. The map the downstream agent carries is the linked reference at each layer, not the entire territory of raw findings decoded into its context window.
This symmetry is the core architectural insight. The same constraint, finite context window and nonlinear quality degradation from overload, applies whether the agent is reading a skill description or reading a research artifact. The same solution, progressive disclosure via layered, linked, on-demand-loadable units, applies whether the agent is loading procedural knowledge or receiving declarative findings. The artifact pyramid is simply the agentskills.io pattern reflected outward: the same three-tier model, the same context economy discipline, applied to what agents write rather than what they read.
FREE OPEN SOURCE SKILL
Put the artifact pyramid into practice today.
We have created a free, open source artifact-pyramids agent skill for the agentskills.io standard. Install it in any compatible agent and your researcher profile will automatically produce three-layer pyramid outputs — summary, analysis files, dossiers — instead of flat reports. No configuration required. Just point your agent at the skill and it works.
What This Means for Enterprise Teams
For agentic AI research to scale across multi-agent pipelines, this symmetry is not optional. A system where agents consume progressively but produce monolithically is a system where, as we explored in the AI Amplification Matrix, the bottleneck has shifted from input context management to output artifact design.
The artifact pyramid closes that gap. It makes progressive disclosure a property of the full communication cycle: what agents receive, what they produce, and how both are structured for the finite context windows they share.
Enterprise teams building multi-agent systems today should evaluate their research output pipeline with the same rigor they apply to their skill loading pipeline. If your product-manager agent and your data-architect agent are receiving the same flat document, you haven't solved the context economy problem. You have only delayed it by one stage.
The artifact pyramid is a framework for closing that gap. It's built on the same first principles that made progressive disclosure successful on the input side. It applies those principles symmetrically to what agents produce. And with tools like GroktoCrawl and the agentskills.io standard already providing the infrastructure, it is ready to implement today. The question is not whether your agents can benefit from progressive research artifacts. They already can. The question is whether your research output pipeline has caught up to the rest of your agent architecture.